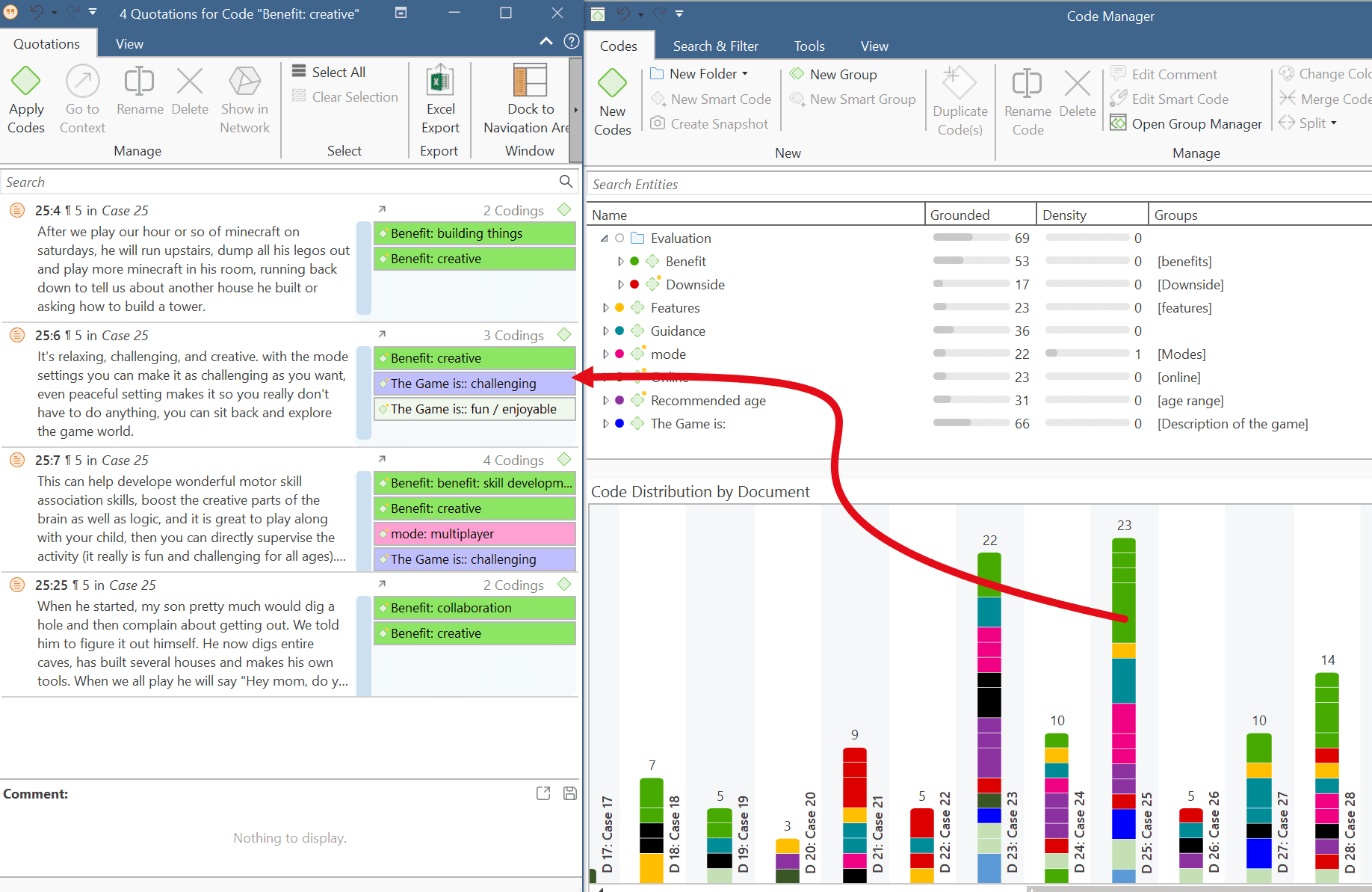
Analysing Code Distributions
Code distributions are displayed in the Document Manager and in the Code Manager in the form of bar charts. In the document manager you will see a bar for each code. The higher the bar, the more often the code was used. In the Code Manager each bar stands for a document. Within the bar you can see how the codes are distributed in the document.
After you've encoded the data, a look at the code distribution gives you a feel for the data. Which topics were mentioned more or less frequently, by whom, is there a difference between different groups of respondents? How are the topics distributed?
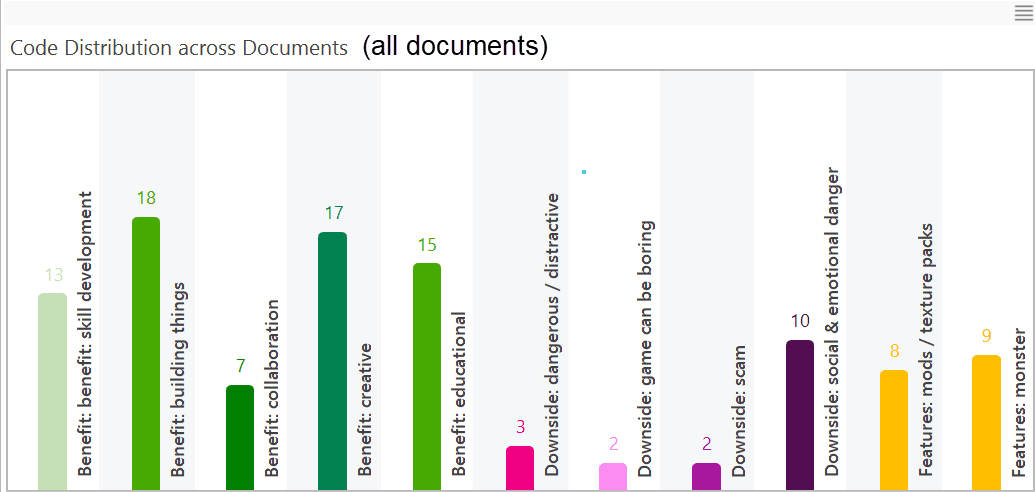
Code Distribution across Documents
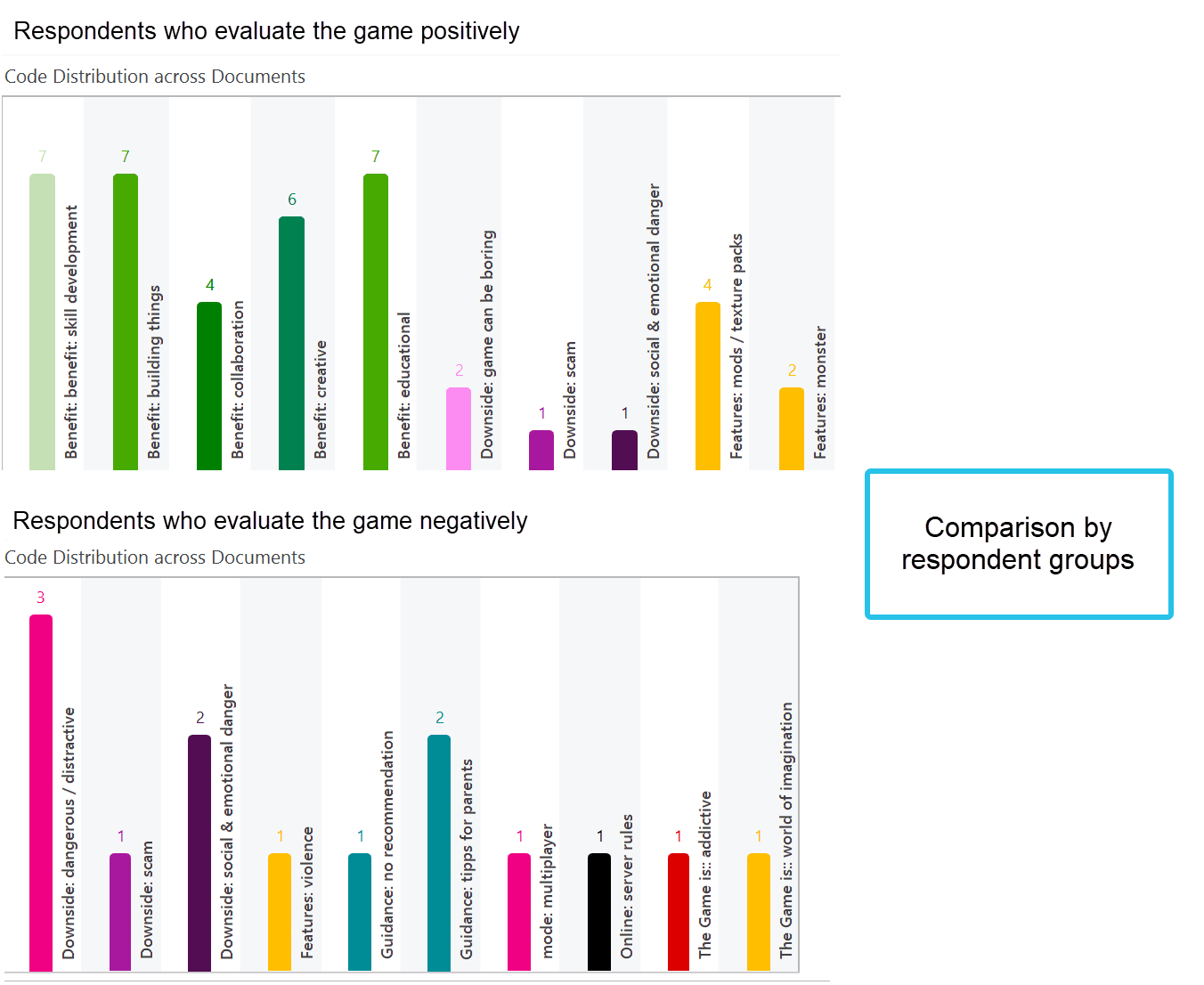
In the first image below, you see the distribution of three categories: benefits, downsides and features of the computer game Minecraft across all documents. In the second image, the data have been filtered a) by respondents who evaluated the game positively, and b) by respondents who evaluated the game negatively. You can see very quickly that there is a difference. Respondents who evaluated the game negatively did not mention any benefits (green bars).
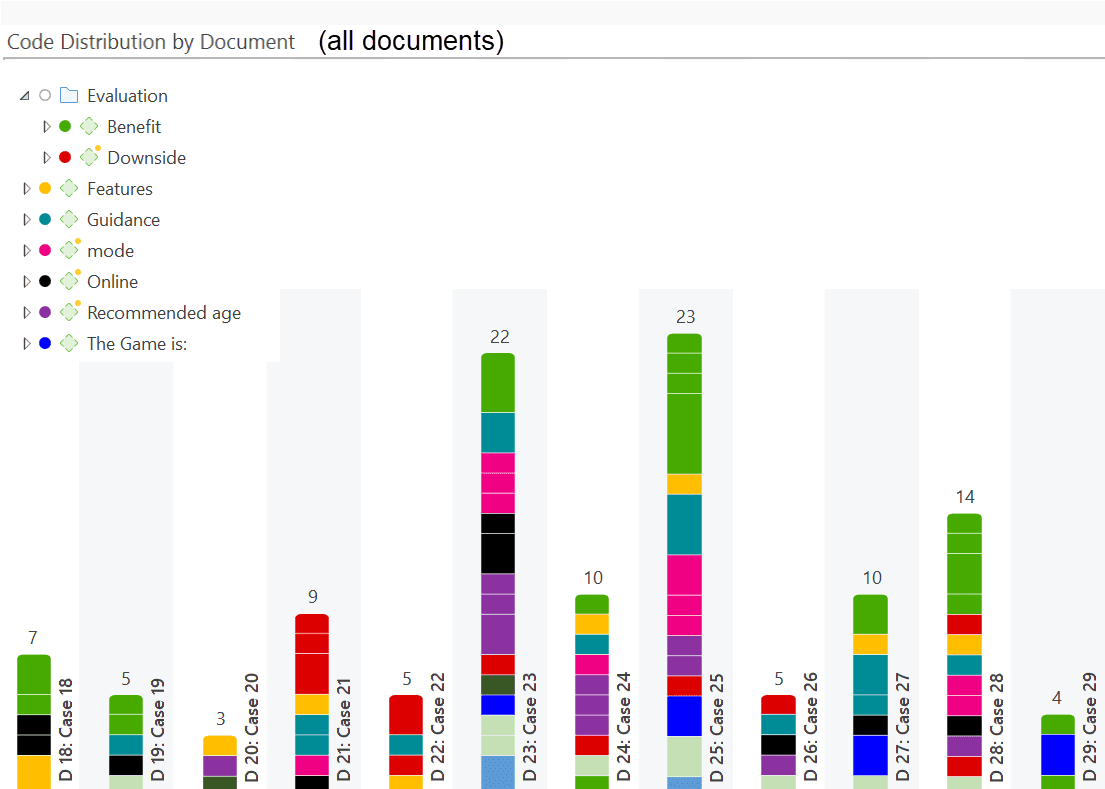
Code Distribution by Documents
In the image below you see the distribution of the various high level topic within each document. We see for instance that case 23 and case 25 talk about a wider variety of topics than the other respondents. In order to generate this graphic, each category has a different color and all subcodes within a category are also colored with the same color.
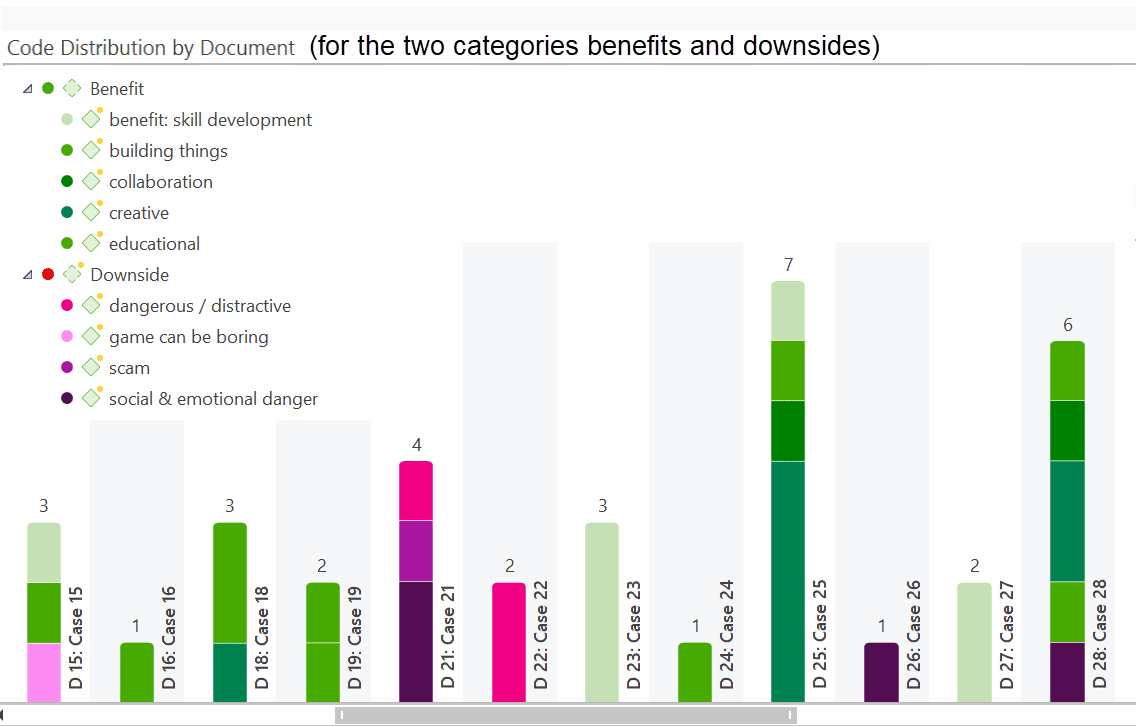
 In the image below, the focus is on two categories, benefits and downsides. In order to be able to differentiate between the various subcodes of a category, each subcode has a different color. If you analyse interview data for instance, this is a great way to go through your data, category for category and compare the respondents' answers. You see who talked about benefits or downsides, strategies or consequences and about which aspects of those major themes they talked about.
In the image below, the focus is on two categories, benefits and downsides. In order to be able to differentiate between the various subcodes of a category, each subcode has a different color. If you analyse interview data for instance, this is a great way to go through your data, category for category and compare the respondents' answers. You see who talked about benefits or downsides, strategies or consequences and about which aspects of those major themes they talked about.
 With a click on a bar, you can retrieve the coded data per code for each respondent.
With a click on a bar, you can retrieve the coded data per code for each respondent.