
Code-Document Table: Normalization
If documents are of unequal length, or document groups of unequal size, the absolute frequencies might be misleading as a measure of comparison. If you conduct interviews, and some interviews are only half an hour long and others 2 hours, the chance someone talks about certain issues and how often during the interview is higher in the long interviews. Thus, if you were to compare absolute numbers, the results might just reflect the different durations of the interviews. The same applies if you analyse reports. If one report is 25 pages long and another 100 and the full reports are coded, absolute frequencies are not a valid measure for comparison. The total number of quotations in a document, or a group of documents (see first row) can help you to decide whether normalization of the data is appropriate.
If you normalize the data the number of codings are adjusted. As benchmark, the document / document group column or row with the highest total is used. The images below show an example.
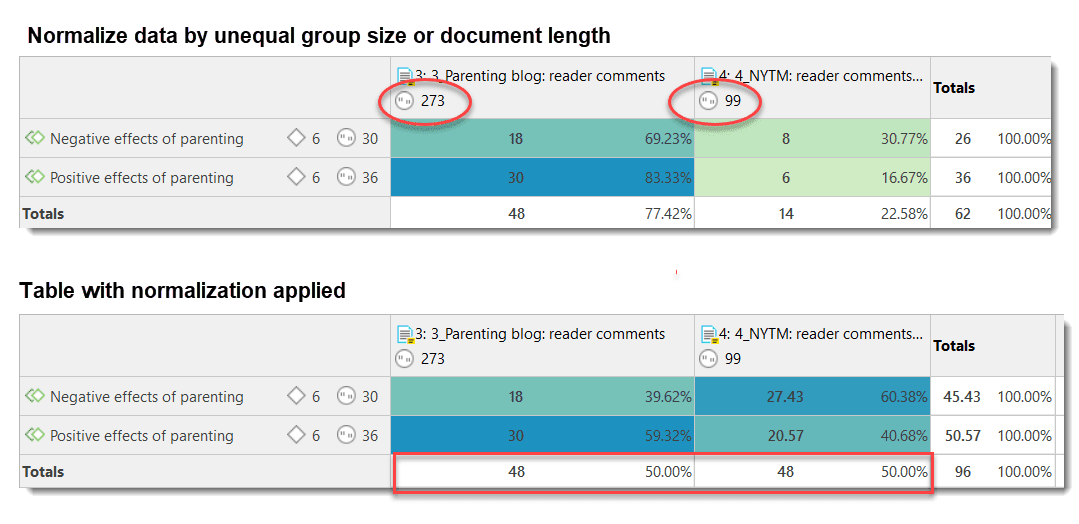 The number of quotations in each document is very different, 273 vs. 99. In fact document 3 is also three times as long as document 4. Therefore, it is not surprising that it contains more quotations. Interpreting the numerical results based on absolute numbers would be misleading. When normalizing the data, the quotation count for the selected code for the document with the lower number of quotations is adjusted; here by the factor 48/14 = 3,428 (rounded at the third digit).
The number of quotations in each document is very different, 273 vs. 99. In fact document 3 is also three times as long as document 4. Therefore, it is not surprising that it contains more quotations. Interpreting the numerical results based on absolute numbers would be misleading. When normalizing the data, the quotation count for the selected code for the document with the lower number of quotations is adjusted; here by the factor 48/14 = 3,428 (rounded at the third digit).
As you can see from the table with the normalized data, this changes the results and also the interpretation. As you don't have to rely on the numbers when working with ATLAS.ti, you can click on each cell and read the data behind it, before you then write up the results in a memo.
As normalization often results in uneven numbers, it is useful to work with relative rather than absolute frequencies. See Relative Frequencies.