
Preface
ATLAS.ti 9 Quick Tour
Copyright © by ATLAS.ti Scientific Software Development GmbH, Berlin. All rights reserved.
Document version: 9.0.0.214 (15.12.2021 19:52:02)
Author: Dr. Susanne Friese
Copying or duplicating this document or any part thereof is a violation of applicable law. No part of this manual may be reproduced or transmitted in any form or by any means, electronic or mechanical, including, but not limited to, photocopying, without written permission from ATLAS.ti Scientific Software Development GmbH.
Trademarks: ATLAS.ti is a registered trademark of ATLAS.ti Scientific Software Development GmbH. Adobe Acrobat is a trademark of Adobe Systems Incorporated; Microsoft, Windows, Excel, and other Microsoft products referenced herein are either trademarks of Microsoft Corporation in the United States and/or in other countries. Google Earth is a trademark of Google, Inc. All other product names and any registered and unregistered trademarks mentioned in this document are used for identification purposes only and remain the exclusive property of their respective owners.
Please always update to the latest versions of ATLAS.ti when notified during application start.
About this Quick Tour
This Quick Tour describes the main functions of ATLAS.ti 9, so that you get a quick overview of how to use the software and get started with your analysis. If you need more detail or information about functions that are not described in this manual, you can always use the online help by pressing the F1 key.
It is not required that you read the manual sequentially from the beginning to the end. Feel free to skip sections that describe concepts you are already familiar with, jump directly to sections that describe functions you are interested in, or simply use it as a reference guide to look up information on certain key features.
The sequence of the chapters follows the steps that are necessary to start and work on an ATLAS.ti project. At first, we introduce you to the main concepts and give an overview of the main steps when analysing data with ATLAS.ti. Then we walk you through step-by-step:
- How to create a project and add documents.
- How to code you data.
- How to explore your data and write memos and comments.
- How to analyse your data and build conceptual networks.
- How to create reports.
Some general familiarity with concepts and procedures relating to the operating system and computing in general (e.g., selecting techniques, files, folders, paths) is assumed.
This is largely a technical document. You should not expect any detailed discussion of methodological aspects of qualitative research. However, you find some recommendations about how to code your data, how to build a coding system for a computer-assisted qualitative data analysis, or how to work with memos including references to academic sources. At the end of some chapter you find longer lists of articles, book chapters or books for further study.
Useful Resources for Getting Started
Video tutorials are available for each main topic. You find links to those tutorials at the beginning of the chapters introducing a new main topic.
To those seeking in-depth instruction on methodological aspects, the ATLAS.ti Training Center offers a full complement of dedicated ATLAS.ti training events worldwide, both through online courses and face-to-face seminars in nearly all parts of the world. Visit the ATLAS.ti Academy for more information.
ATLAS.ti Account and Licence Activation
For further information on Multi-User License Management, see our Guide for License Holders & Administrators.
Requesting a Trial Version
Go to https://my.atlasti.com/ to create an account.
Confirm your email address.
Request a trial license by clicking on Trial Desktop.
This brings you to the Cleverbridge Website.
Enter the required information and download the software.
If you do not want to download the software immediately, you can always do this later in your ATLAS.ti account. To do so, select My Applications.
The trial version can be used for 5 active days by one person on one computer within a period of 3 months. At the end of the test period, you can continue to use ATLAS.ti with limited functionality. If your project contains more than 10 documents, 50 quotations or 25 codes, you can no longer save any changes. Thus, ATLAS.ti then becomes a read-only version.
You can initiate the purchase of a full licence from your ATLAS.ti account. After activating the licence, and the program can be used again at full capacity. You can also continue to work on your project without any data loss.
You cannot install a trial version again on the same computer.
Activating a Licence
You need to make an online connection at least once to activate your licence. Once the account it activated, you can work offline and no further online connection is required. Please note, if you are using a seat that is part of a multi-user licence, you will blog the seat if you are offline.
If you have purchased an individual license from the ATLAS.ti web shop, your license has been added to your account. The next step is to activate it.
Similarly, if you are a member of a team of users under a multi-user license, you have received a license key, an invitation code, or invitation link from the person who manages the license.
The ATLAS.ti License Management System allocates seats of multi-user license dynamically. This means, you are assigned the first free seat under your license. If all seats are occupied, you will be allocated the next seat that opens up.
Log in to your ATLAS.ti account.
Navigate to License Management (the default page) and enter either the license key, or the invite code that you were given by the license owner/license manager.
Click Activate License.
Start ATLAS.ti on your computer and click Check For Updated License and follow the on-screen instructions to complete a few easy steps to activate your license.
Your installation is now activated, and you can start using ATLAS.ti.
Accessing Your Account from within ATLAS.ti
On the opening screen, click on the user avatar. If you have not added a picture yet, it will show the first two letters of your account name.
![]()
Click on Manage Account. This takes you to the login screen. Enter your log in information (email and password) to access your account.
Logging Out
It is important to understand that the installation of ATLAS.ti is independent of the licencing of the software. You can have ATLAS.ti installed on as many computers as you want. A single-user licence gives you the right to use it on two computers, e.g. your desktop computer at the office and your laptop at home; or your Windows computer and your Mac computer; or the Cloud version and a desktop version. If you want to use ATLAS.ti on a third computer, or if you get a new computer, make sure you log out at the computer that you do no longer want to use. If you have been invited to use a multi-user license, you will have one seat for the time when using ATLAS.ti.
There are two ways how to log out to free a seat:
Click on the user avatar in the welcome screen and click Log Out.
If you forgot to log out in ATLAS.ti, you can always access your user account via a web browser:
Go to https://my.atlasti.com/. Enter your email address and password to log in.
Select the Log Out option at the bottom left above your avatar in your ATLAS.ti account.
Working Off-Line
When starting ATLAS.ti, it checks whether you have a valid licence. If you know that you won't have online access for a given period, you can set your licence to off-line work for a specified period.
If you have a licence that does not expire, the maximum off-line period is four months. If you have a lease licence, the maximum period is dependent on the expiration date of your lease. This means, if your licence expires in 1 month, you cannot set the offline period to an additional 3 months.
After the period expired, you need to connect to the Internet again to verify your licence.
Limited Version after Licence Expiration
Once the trial period or a time limited licence expire, the program is converted into a limited version. You can open, read and review projects, but you can only save projects that do not exceed a certain limit (see below). Thus, you can still use ATLAS.ti as a read-only version.
You cannot install a trial version again on the same computer.
Restrictions of the Limited Version
- 10 primary documents
- 50 quotations
- 25 codes
- 2 memos
- 2 network views
- auto backup is disabled
Introduction
ATLAS.ti is a powerful workbench for the qualitative analysis of larger bodies of textual, graphical, audio, and video data. It offers a variety of tools for accomplishing the tasks associated with any systematic approach to unstructured data, i. e., data that cannot be meaningfully analyzed by formal, statistical approaches. In the course of such a qualitative analysis, ATLAS.ti helps you to explore the complex phenomena hidden in your data. For coping with the inherent complexity of the tasks and the data, ATLAS.ti offers a powerful and intuitive environment that keeps you focused on the analyzed materials. It offers tools to manage, extract, compare, explore, and reassemble meaningful pieces from large amounts of data in creative, flexible, yet systematic ways.
The VISE Principle
The main principles of the ATLAS.ti philosophy are best encapsulated by the acronym VISE, which stands for
- Visualization
- Immersion
- Serendipity
- Exploration
Visualization
The visualization component of the program means directly supports the way human beings think, plan, and approach solutions in creative, yet systematic ways.
Tools are available to visualize complex properties and relations between the entities accumulated during the process of eliciting meaning and structure from the analyzed data.
The process is designed to keep the necessary operations close to the data to which they are applied. The visual approach of the interface keeps you focused on the data, and quite often the functions you need are just a few mouse clicks away.

Immersion
Another fundamental design aspect of the software is to offer tools that allow you to become fully immersed in your data. No matter where you are in the software, you always have access to the source data. Reading and re-reading your data, viewing them in different ways and writing down your thoughts and ideas while you are doing it, are important aspects of the analytical process. And, it is through this engagement with the data that you develop creative insights.
Serendipity
Webster's Dictionary defines serendipity as a seeming gift for making fortunate discoveries accidentally. Other meanings are: Fortunate accidents, lucky discoveries. In the context of information systems, one should add: Finding something without having actually searched for it.
The term serendipity can be equated with an intuitive approach to data. A typical operation that relies on the serendipity effect is browsing. This information-seeking method is a genuinely human activity: When you spend a day in the local library (or on the World Wide Web), you often start with searching for particular books (or key words). But after a short while, you typically find yourself increasingly engaged in browsing through books that were not exactly what you originally had in mind - but that lead to interesting discoveries.
Examples of tools and procedures ATLAS.ti offers for exploiting the concept of serendipity are the Search & Code Tools, the Word Clouds and Lists, the Quotation Reader, the interactive margin area, or the hypertext functionality.
Exploration
Exploration is closely related to the above principles. Through an exploratory, yet systematic approach to your data (as opposed to a mere bureaucratic handling), it is assumed that especially constructive activities like theory building will be of great benefit. The entire program's concept, including the process of getting acquainted with its particular idiosyncrasies, is particularly conducive to an exploratory, discovery-oriented approach.
Areas of Application
ATLAS.ti serves as a powerful utility for qualitative analysis of textual, graphical, audio, and video data. The content or subject matter of these materials is in no way limited to any one particular field of scientific or scholarly investigation.
Its emphasis is on qualitative, rather than quantitative, analysis, i. e., determining the elements that comprise the primary data material and interpreting their meaning. A related term would be "knowledge management," which emphasizes the transformation of data into useful knowledge.
ATLAS.ti can be of great help in any field where this kind of soft data analysis is carried out. While ATLAS.ti was originally designed with the social scientist in mind, it is now being put to use in areas that we had not really anticipated. Such areas include psychology, literature, medicine, software engineering, user experience research, quality control, criminology, administration, text linguistics, stylistics, knowledge elicitation, history, geography, theology, and law, to name just some of the more prominent.
Emerging daily are numerous new fields that can also take full advantage of the program's facilities for working with graphical, audio, and video data. A few examples:
- Anthropology: Micro-gestures, mimics, maps, geographical locations, observations, field notes
- Architecture: Annotated floor plans
- Art / Art History: Detailed interpretative descriptions of paintings or educational explanations of style
- Business Administration: Analysis of interviews, reports, web pages
- Criminology: Analysis of letters, finger prints, photographs, surveillance data
- Geography and Cultural Geography: Analysis of maps, locations
- Graphology: Micro comments to handwriting features.
- Industrial Quality Assurance: Analyzing video taped user-system interaction
- Medicine and health care practice: Analysis of X-ray images, CAT scans, microscope samples, video data of patient care, training of health personal using video data
- Media Studies: Analysis of films, TV shows, online communities
- Tourism: Maps, locations, visitor reviews
Many more applications from a host of academic and professional fields are the reality. The fundamental design objective in creating ATLAS.ti was to develop a tool that effectively supports the human interpreter, particularly in handling relatively large amounts of research material, notes, and associated theories.
Although ATLAS.ti facilitates many of the activities involved in qualitative data analysis and interpretation (particularly selecting, tagging data, and annotating), its purpose is not to fully automate these processes. Automatic interpretation of text cannot succeed in grasping the complexity, lack of explicitness, or contextuality of everyday or scientific knowledge. In fact, ATLAS.ti was designed to be more than a single tool - think of it as a professional workbench that provides a broad selection of effective tools for a variety of problems and tasks.
ATLAS.ti - The Knowledge Workbench
The image of ATLAS.ti as a knowledge workbench is more than just a lively analogy. Analytical work involves tangible elements: research material requires piecework, assembly, reworking, complex layouts, and some special tools. A well-stocked workbench provides you with the necessary instruments to thoroughly analyze and evaluate, search and query your data, to capture, visualize and share your findings.
Some Basic Terms
To understand how ATLAS.ti handles data, visualize your entire project as an intelligent container that keeps track of all your data. This container is your ATLAS.ti project.
The project keeps track of the paths to your source data and stores the codes, code groups, networks, etc. that you develop during your work. Your source data files are copied and stored in a repository. The standard option is for ATLAS.ti to manage the documents for you in its internal database. If you work with larger audio or video files, they can be linked to your project to preserve disk space. All files that you assign to the project (except those externally linked) are copied, i.e., a duplicate is made for ATLAS.ti's exclusive use. Your original files remain intact and untouched in their original location.
Your source data can consist of text documents (such as interview or focus group transcripts, reports, observational notes); images (photos, screen shots, diagrams),audio recordings (interviews, broadcasts, music), video clips (audiovisual material),PDF files (papers, brochures, reports, articles or book chapters for a literature review), geo data (locative data using Open Street Map), and tweets from a twitter query.
Once your various documents are added or linked to an ATLAS.ti project, your real work can begin. Most commonly, early project stages involve coding different data sources.
Selecting interesting segments in your data and coding them is the basic activity you engage in when using ATLAS.ti, and it is the basis of everything else you will do. In practical terms, coding refers to the process of assigning codes to segments of information that are of interest to your research objectives. We have modeled this function to correspond with the time-honored practice of marking (underlining or highlighting) and annotating text passages in a book or other documents.
In its central conceptual underpinnings, ATLAS.ti has drawn deliberately from what might be called the paper and pencil paradigm. The user interface is designed accordingly, and many of its processes are based on - and thus can be better understood by - this analogy.
Because of this highly intuitive design principle, you will quickly come to appreciate the margin area as one of your most central and preferred work space - even though ATLAS.ti almost always offers a variety of ways to accomplish any given task.
General Steps when Working with ATLAS.ti
The following sequence of steps is, of course, not mandatory, but describes a common script:
-
Create a project, an idea container, meant to enclose your data, all your findings, codes, memos, and structures under a single name. See Creating a New Project.
-
Next, add documents, text, graphic, audio and video files, or geo documents to your ATLAS.ti project. See Adding Documents.
-
Organize your documents. See Working With Groups.
-
Read and select text passages or identify areas in an image or select segments on the time line of an audio or video file that are of further interest, assign key words (codes), and write comments and memos that contain your thinking about the data. Build a coding system. See Working With Comments And Memos and Working With Codes.
-
Compare data segments based on the codes you have assigned; possibly add more data files to the project. See for example Retrieving Coded Data.
-
Query the data based on your research questions utilizing the different tools ATLAS.ti provides. The key words to look for are: simple retrieval, complex code retrievals using the Query Tool, simple or complex retrievals in combination with variables via the scope button, applying global filters, the Code Co-occurrence Tools (tree explorer and table), the Code Document Table, data export for further statistical analysis (see Querying Data and Data Export For Further Statistical Analysis.
-
Conceptualize your data further by building networks from the codes and other entities you have created. These networks, together with your codes and memos, form the framework for emerging theory. See Working With Networks.
-
Finally, compile a written report based on the memos you have written throughout the various phases of your project and the networks you have created. See Working With Comments And Memos and Exporting Networks.
For additional reading about working with ATLAS.ti, see The ATLAS.ti Research Blog and The ATLAS.ti conference proceedings.
Main Steps in Working with ATLAS.ti
Video Tutorial: Overview of ATLAS.ti 9 Mac.
Data and Project M
A first important but often neglected aspect of a project is data and project management. The first step is data preparation. You find more information on supported file formats in the section Supported File Formats.
Apart from analyzing your data, you also manage digital content and it is important to know how the software does it. For detailed information, see the section on Project Management.
If you work in a team, please read the following section: Team Work.
Two Principal Modes of Working
There are two principal modes of working with ATLAS.ti, the data level and the conceptual level. The data level includes activities like segmentation of data files; coding text, image, audio, and video passages; and writing comments and memos. The conceptual level focuses on querying data and model-building activities such as linking codes to networks, in addition to writing some more comments and memos.
The figure below illustrates the main steps, starting with the creation of a project, adding documents, identifying interesting things in the data and coding them. Memos and comments can be written at any stage of the process, whereas there is possibly a shift from writing comments to more extensive memo writing during the later stages of the analysis. Once your data is coded, it is ready to be queried using the various analysis tools provided. The insights gained can then be visualized using the ATLAS.ti network function.
Some steps need to be taken in sequence. For instance, logic dictates that you cannot query anything or look for co-occurrences if your data has not yet been coded. But other than that there are no strict rules.
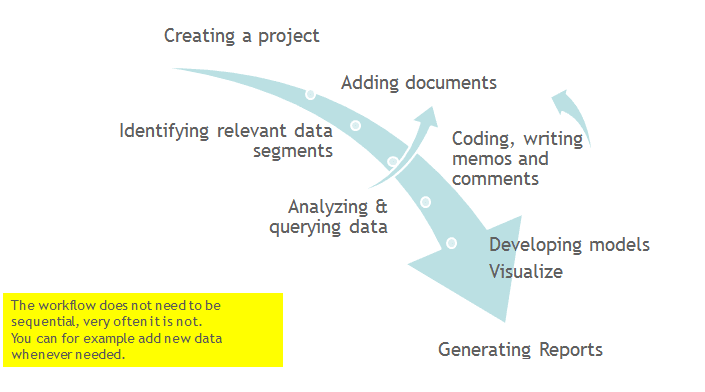
Data Level Work
Data-level activities include Exploring Data using word clouds and word lists, segmenting the data that you have assigned to a project into quotations, adding comments to respective passages note-making/annotating, linking data segments to each other called hyperlinking in ATLAS.ti, and coding data segments and memos to facilitate their later retrieval. The act of comparing noteworthy segments leads to a creative conceptualization phase that involves higher-level interpretive work and theory-building.
ATLAS.ti assists you in all of these tasks and provides a comprehensive overview of your work as well as rapid search, retrieval, and browsing functions.
Within ATLAS.ti, initial ideas often find expression through their assignment to a code or memo, to which similar ideas or text selections also become assigned. ATLAS.ti provides the researcher with a highly effective means for quickly retrieving all data selections and notes relevant to one idea.
Conceptual Level Work
Beyond coding and simple data retrieval, ATLAS.ti allows you to query your data in lots of different ways, combining complex code queries with variables, exploring relationships between codes and to visualize your findings using the network tool.
ATLAS.ti allows you to visually connect selected passages, memos, and codes into diagrams that graphically outline complex relations. This feature virtually transforms your text-based work space into a graphical playground where you can construct concepts and theories based on relationships between codes, data segments, or memos.
This process sometimes uncovers other relations in the data that were not obvious before and still allows you the ability to instantly revert to your notes or primary data selection. - For more detail, see Querying Data and Working With Networks.
Project Management
Opening a Project
To open a project, click on a project on the Welcome Screen, or if a project is already open, and you want to open another one, select Project > Open.
Creating a New Project
If you just started ATLAS.ti,
On the welcome screen click on the button: New Project.
Enter a name for the project and click on Create.
 If a project is already open,
If a project is already open,
click on Project > New.
Inst
Enter a name for the project and click Create.
Saving
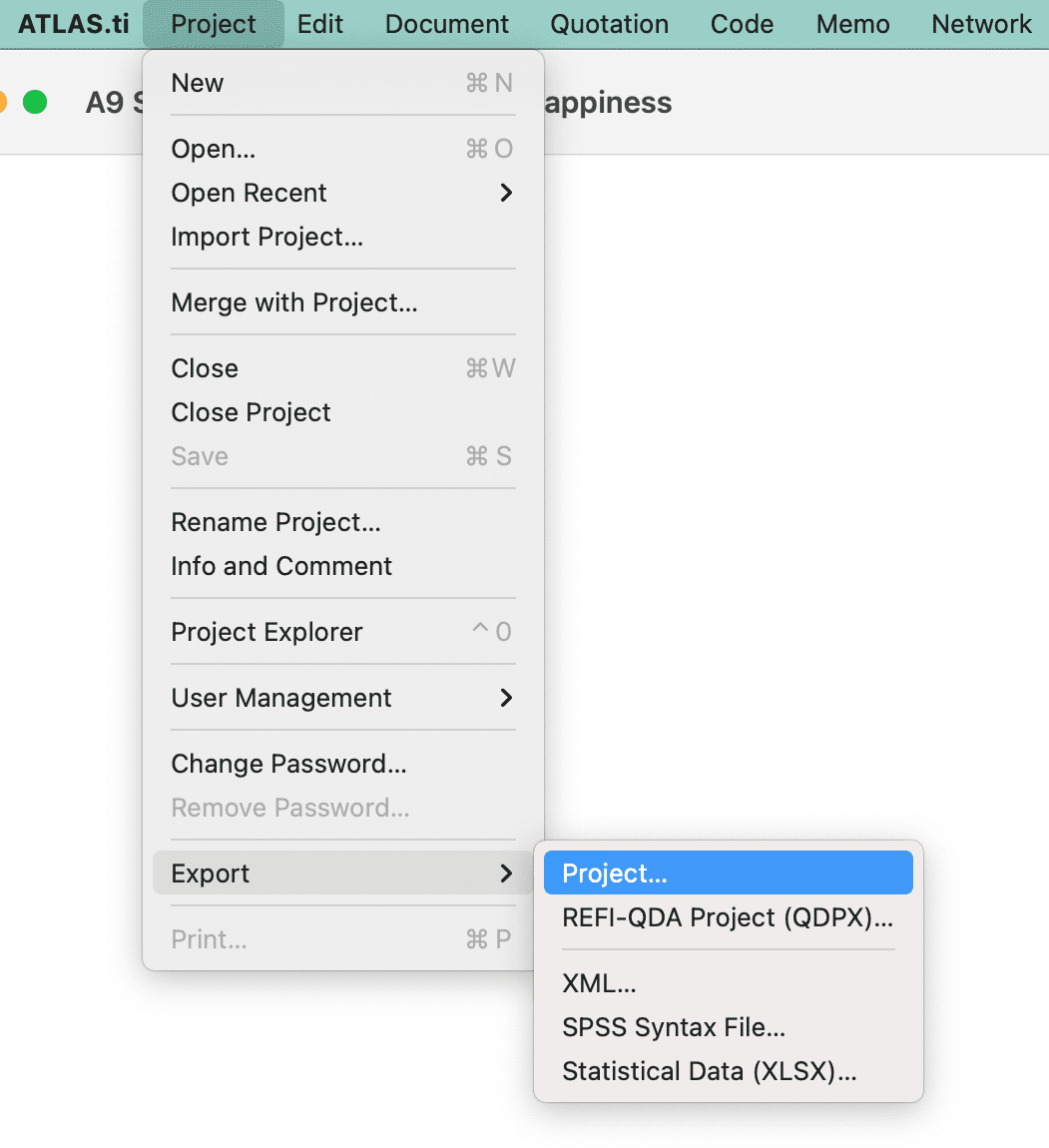
To save a project, select Project > Save from the main menu or use key combination command + S. The project is saved as internal ATLAS.ti file in the ATLAS.ti library. The default location for the library is the application folder on your computer. See Where Does ATLAS.ti Store Project Data?. It is possible to either change the default location for the ATLAS.ti library or to create new libraries. See About ATLAS.ti Libraries See the full manual for further detail.
If you want to save an external copy of your project, you need to export it. See below 'Creating a Project Backup'.
Renaming a Project
Select Project > Rename from the main menu.
Deleting a Project
inst
You can delete projects from the opening screen, either when you start ATLAS.ti or by selecting Project > Open.
inst
Select a project on the opening screen, right-click on a project and select the option Delete.
You will be asked to confirm the deletion as this is a permanent action that cannot be undone.
Creating a Project Backup
Please export your projects on a regular basis and store the bundle files in a safe location. In case something happens to your computer, you still have a copy of your project to fall back on!
To create a backup of your project, you need to export it and save it as project bundle file on your computer, an external drive, a server or cloud location.
A project bundle file serves as external backup of your project independent of the ATLAS.ti installation on your computer.
-
The project bundle file contains all documents that you have added or linked to a project, and the project file that contains all of your coding, the codes, all memos,comments, networks and links. Large audio or video files can be excluded from the bundle.
-
Project bundle files are also used to transfer projects between computers. They can be read by both ATLAS.ti Mac and Windows. See Project Transfer.
-
If your project contains linked documents, they can be excluded when creating a project bundle file. See "Creating Partial Bundles" below.
Project Transfer
In order to transfer a project to a different computer, e.g., to share it with team members, you need to export it and create a project bundle file. See above.
ATLAS.ti desktop project can currently not be imported into ATLAS.ti Web. It is however possible to import ATLAS.ti Web projects into the desktop version.
ATLAS.ti 9 projects cannot be used in previous versions.
Supported File Formats
In principle, most textual, graphical, and multimedia formats are supported by ATLAS.ti. For some formats, their suitability depends on the state of your Windows system. Before deciding to use an exotic data format, you should check if this format is available and if it is sufficiently supported by your Windows system.
Textual Documents
The following file formats are supported:
| Format | File Type |
|---|---|
| MS Word | .doc; .docx; .rtf |
| Open Office | .odt |
| HyperText Markup Language | .htm; .html |
| Plain text | .txt |
| other | .ooxml |
Text documents can be edited in ATLAS.ti. This is useful to correct transcription errors, to change formatting, or to add missing information. When adding an empty text document to an ATLAS.ti project, you can also transcribe your data in ATLAS.ti. We however recommend using a dedicated transcription tool or use automated transcriptions. You can add transcripts with timestamps and synchronize them with the original audio or video file. For this you use Multimedia Transcripts.
Transcripts
You can prepare your own transcripts in ATLAS.ti, or import transcripts that have been created elsewhere.
This could mean - you or another person transcribing data for you - have used a specialized transcription software like:
- Easytranscript
- f4 & f5 transcript
- Transcribe
- Inqsribe
- Transana
- ExpressSribe, a.o.;
Another source are transcript prepared automatically by services like Microsoft Teams, Zoom or YouTube in SRT or VTT format. Examples of supported services are:
- MS Teams
- Zoom
- YouTube
- Happyscribe
- Trint
- Descript
- Sonix
- Rev.com
- Panopto
- Transcribe by Wreally
- Temi
- Simon Says
- Vimeo
- Amberscript
- Otter.ai
- Vocalmatic
- eStream
For further information on how to import transcripts from these services, see Importing Automated Transcripts in VTT and SRT format
PDF files (Text and Graphic)
PDF files are perfect if you need the original layout. When PDF was invented, its goal was to preserve the same layout for onscreen display and in print.
If the PDF file has annotations, they are displayed in ATLAS.ti. However, they cannot be edited.
When preparing PDFs, you need to pay attention that you prepare a text PDF file and not a graphic PDF. If you do the latter, then ATLAS.ti treats it as a graphic file, and you cannot search it or retrieve text.
When scanning a text from paper, you need to use character recognition software (OCR, frequently provided with your scanner) in order to create a text PDF file. Another option is to apply character recognition in your PDF reader/writer software.
When you retrieve text from a coded PDF segment the output will be rich text. Thus, you may loose the original layout. This is due to the nature of PDF as mentioned above. It is a layout format and not meant for text processing.
Images
Supported graphic file formats are: bmp, gif, jpeg, jpg, png, tif and tiff.
Size recommendation: Digital cameras and scanners often create images with a resolution that significantly exceeds the resolution of your screen. When preparing a graphic file for use with ATLAS.ti, use image-processing software to reduce the size so that the graphics are comfortably displayed on your computer screen. ATLAS.ti does resize the images if they are too big. But this requires additional computer resources and unnecessarily uses space on your computer hard disk.
To resize and image manually, you can use the zoom function via the mouse wheel or the zoom button in ATLAS.ti.
Audio- and Video Documents
Supported audio file formats are: aac, m4a, mp3, mp4. Supported video file formats are: avi, m4v, mov, mp4.
For audio files, our recommendation is to use *.mp3 files with AAC audio, and for video files *.mp4 file with AAC audio and H.264 video. These can be played both in the Windows and in the Mac version. As video files can be quite sizable, we recommend to link video files to an ATLAS.ti projects rather than to import them. See Adding Documents for further information.
Geo Documents
When you want to work with Geo data, you only need to add a new Geo Document to your ATLAS.ti project. This opens Apple Maps. To navigate to a specific region or location on the map, enter an address or location name in the search field. For more information, see Working With Geo Docs.
Survey Data
The survey import option allows you to import data via an Excel spreadsheet (.xls or .xlsx files). Its main purpose is to support the analysis of open-ended questions. However, this option can also be used for other case-based data that can easily be prepared in form of an Excel table.
In addition to the answers to open-ended questions, data attributes (variables) can also be imported. These will be turned into document groups in ATLAS.ti. For more information, see Working With Survey Data.
Reference Manager Data
In order to support doing a Literature Review with ATLAS.ti, you can import articles from reference managers. The requirement is that you are using a reference manager that can export data as Endnote XML file like Endnote, Mendeley, Zotero, or Reference Manager.
If your reference manager cannot export data in Endnote xml format, you can export data in RIS or BIB format and use the free version of Mendeley or Zotero to produce the xml output for ATLAS.ti.
See Working With Reference Manager Data.
You can collect data from Twitter searching for keywords, hashtags, users, etc. ATLAS.ti can collect tweets that are not older than one week !
You need to sign in with your own twitter account to import twitter data to ATLAS.ti. See Working With Twitter Data.
Adding Documents
Video Tutorial: Creating a project and importing data.
What happens when you add documents to a project
All documents that you add to a project are copied, and the copies become internal ATLAS.ti files. This means, strictly speaking, that ATLAS.ti no longer needs the original files. However, we strongly recommend that you keep a backup copy of your original sou
As audio and video files can be quite sizable, you have the option to create an external reference to the files. This means the multimedia documents remain at their original location and are accessed from there. Preferably, these files should not be moved to a different location. If the files need to be moved, you need to re-link the files to your project. ATLAS.ti will alert you, if there is an issue, and a file can no longer be accessed. When you add documents to a project, they are stamped with a unique ID. This ID allows ATLAS.ti to detect if documents are the same when merging different projects.
Important Note for Team Projects
When you work in a team and want to work on the same documents, it is important that one person is setting up the project and adds all documents that should be shared. The consequence of not doing is that documents of the same content are duplicated or multiplied during the process of merging projects. See Team Work for further information.
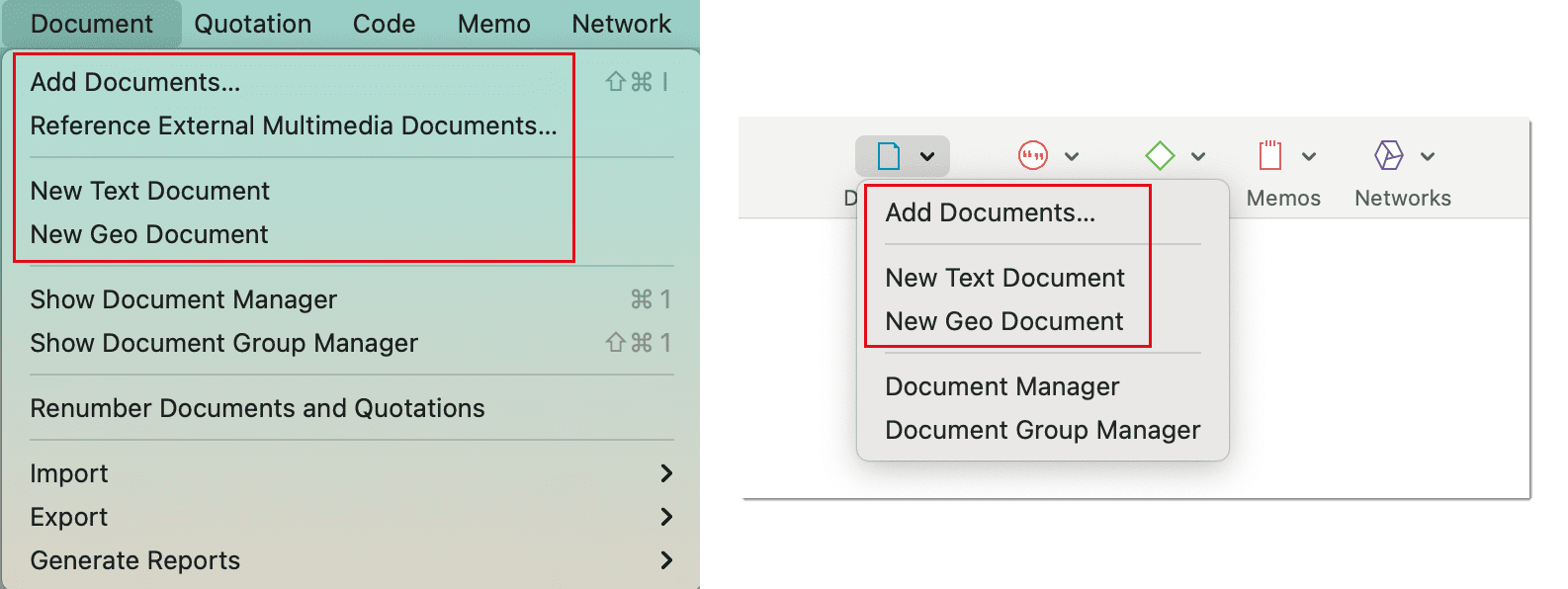
How to Add Documents
From the main menu, select Document > Add Documents... Another option is to open the drop-down menu of the document icon in the toolbar. You can select individual files or folders.
If you want to link a video file, select the option Reference External Multimedia Documents. For further information see Adding Multimedia Data.
If you want write your own text, e.g. in order to transcribe data, select the option New Text Document. For further information see Preparing your own transcript.
All added or linked documents are numbered consecutively starting with 1, 2, 3 and so on.
The default sort order is by name in alphabetical order. The document order cannot be changed in the Mac version.
Size Res
Theoretically, size restrictions do not play a major role due to the way ATLAS.ti handles documents. However, you should bear in mind that your computer's processing speed and storage capacity may affect the performance.
Excessively large documents can be uncomfortable to work with, even when you have an excellently equipped computer. The crucial issue is not always the file size, but rather, in the case of multimedia files, the length of playing time.
For textual documents, the number and size of embedded objects may cause extraordinarily long load times. There is a high likelihood that if a textual document loads slowly in ATLAS.ti, it would also load slowly in WORD or WordPad.
For very long texts or multimedia files, scrolling to exact positions can be cumbersome.
Please keep those issues in mind when preparing your files.
A Word about "Big Data"
Please keep in mind that the focus of ATLAS.ti is to support qualitative data analysis and to a lesser extent the analysis of qualitative data.
Big data is a buzz word nowadays, and a lot of big data often comes as text or images, hence could be considered qualitative. ATLAS.ti, however, is not suited for true big data analysis, which is not the same as qualitative data analysis.
As point of orientation, coding can be supported using the auto coding feature. However, you still need to read and correct the coding, and most coding in ATLAS.ti is done while the researcher reads the data and creates or selects and applies a code that fits.
A project is too large if you have so much data that you need to rely on a machine to do all the coding for you and you cannot read what has been coded yourself. If this is the case, ATLAS.ti might not be the right tool for you.
Working With Groups
Groups in ATLAS.ti help you to sort, organize and filter the various entities. Groups are available for documents, codes, memos, and networks.
Common to all groups are:
- An entity can be sorted into multiple groups. For example if you sort a document into the group gender::female, it can also be sorted into other groups like location::urban, or family status::single.
- If you click on a group in a manager, you activate a filter (see below). Then only the items that are in the selected groups are displayed.
- You can combine groups using Boolean operators. See for example Exploring Coded Data.
- You can save a combination of groups for further re-use in form of a smart group.
- You can set groups as global filter.
There are no groups for quotations, as codes already fulfil this function. Codes group quotations that have a similar meaning. Therefore instead of groups, you see the codes in the side panel of the Quotation Manager.
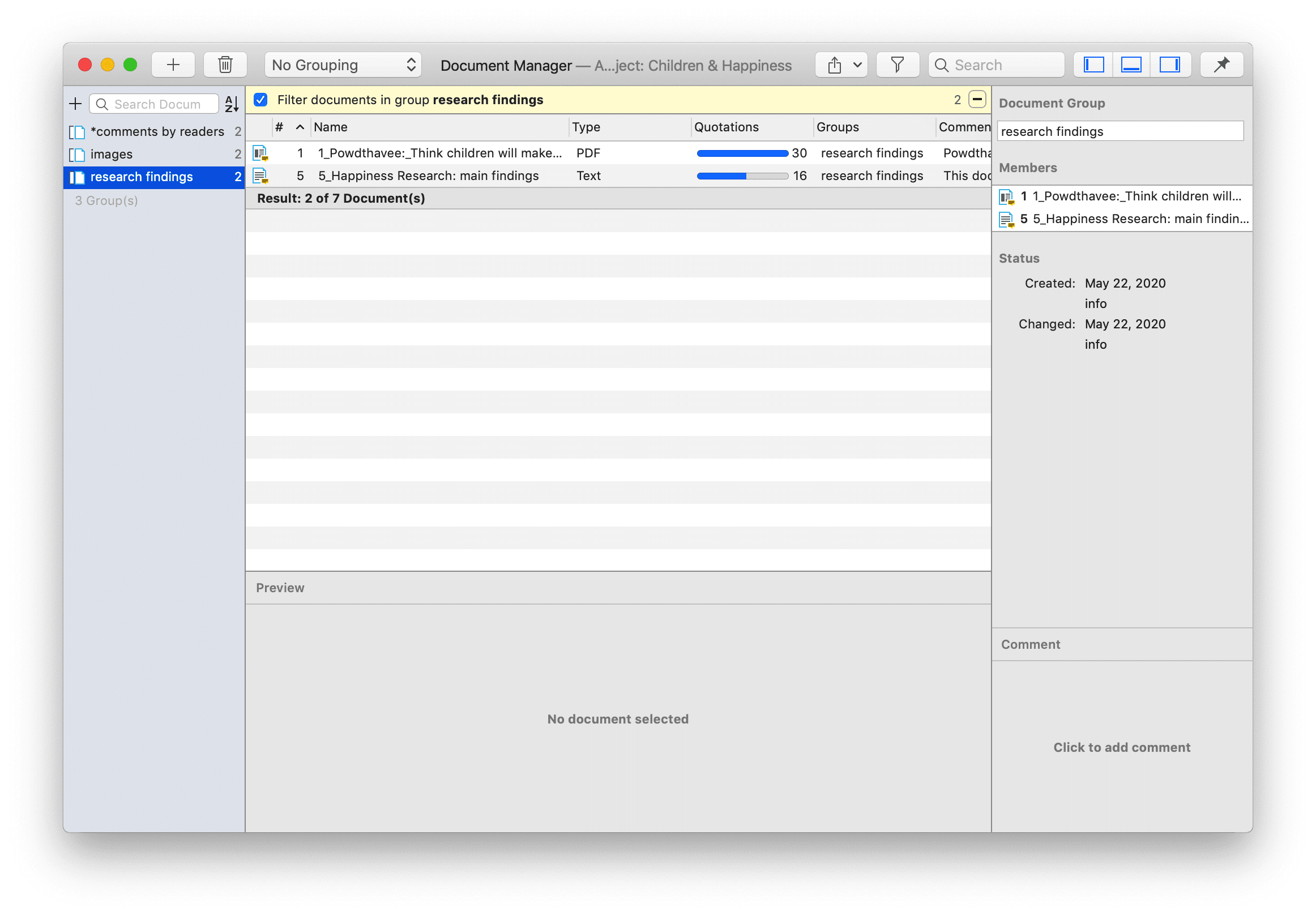
Application of Docume
Often data come from different sources, locations, respondents with various demographic backgrounds etc. To facilitate the handling of the different types of data, they can be organized into document groups. You can also use document groups for administrative purposes in team projects if different coders should code different documents. You can then create a group containing all documents for coder 1, another group containing the documents for coder 2 and so on.
Video Tutorial: Organizing project data - Creating document groups
Another application is the use of document groups for analytic comparisons in the Code Document Table.
Document groups can also be added to Networks and you can show which codes have been applied to which group.
Application of Code Groups
Code groups can be used to sort and organize codes in the Code Manager. Code groups facilitate the navigation of codes in the Code Manager as local filter. See below. Code groups can be used as global filters in analysis.
Code groups can also be used in the Code Document Table for case comparisons.
Users often mistake code groups as a kind of higher order code, which they are not. They do however can be quite useful in building a coding system.
Application of Memo Groups
Memo groups come in handy if you have written lots of memos. You could for example group memos by function: methodological notes, team memos, research diaries, analysis.
If you have multiple memos that contain answers to one research question, you can group all those memos.
If you have multiple memos that contain input for a particular section in the research report, you may want to create a memo group for those.
You find more information on working with memos here: Memos and Comments.
Groups as Filters
Groups are listed in the side panels of the document, code, memo and network manager.
Click on one or more groups to filter the list of items. If you want to select multiple groups hold down the Cmd key.
Once you have set one or more groups as filter, a yellow bar appears above the entity list indicated that a) a filter has been set and b) which one.
To reset the filter to see all entities again, click the minus (-) on the top right-hand side of the yellow bar.
It is also possible to run simple AND and OR queries:
As soon as you select more than one group, you see the word any in blue in the filter bar. This means the default operation is to combine the items of the selected groups with OR.
If you want to filter by the intersection of two or more groups, click on the word "any" and change it to all. This is the Boolean AND operator.
An example would be to filter by all female respondents who live in an urban region. This requires that you have grouped the documents by these two criteria:
- gender::female
- region::urban
The filter would then show the following text: Show documents in all of the groups: gender::female, region::urban. The same options are available for all entity types.
Importing & Exporting Document Groups
You can export and import the list of documents and their groups to and from Excel.
Exporting the data gives you an overview of all your document groups and their members. It can also be used as a starting point to prepare an Excel file for import.
You may want to import a Document Group table, if you already have an Excel file with information about each document like gender, education levels, location, etc.
The content of the Document Group Table consists of the following:
- First column: document name.
- Second and subsequent columns: document groups or document attributes
As document groups in ATLAS.ti are dichotomous, the document groups are listed in the columns, and the cells contain a 0 if the document is not in the group, and a 1 if the document is in the group.
If you do not follow the ATLAS.ti naming conventions (see below), the table will look as follows:

If you use the ATLAS.ti naming convention for document groups: attribute name::attribute label or value, then ATLAS.ti uses the attribute name as column header and the attribute label or value for each cell. For instance, if you have the following groups:
- education::highschool
- education::some college
- education::University degree
- gender::male
- gender::female
- has childre::yes
- has childre::no
- marital status: single
- marital status: married
- marital status: divorced
- number of children:1
- number of children:2
....the Excel table looks as follows:
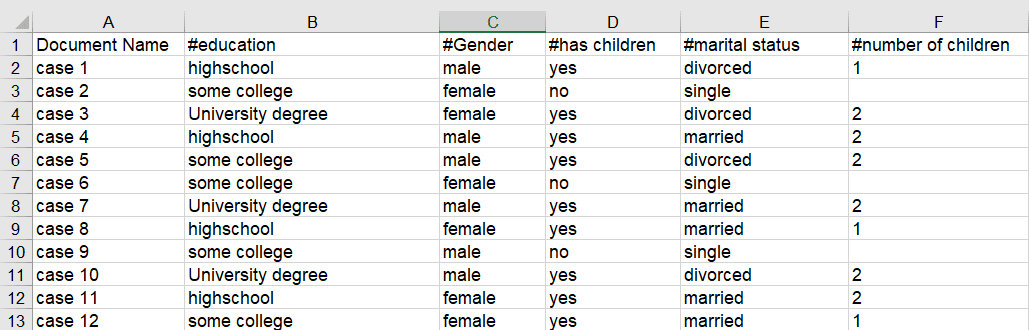
Exporting Document Groups to Excel
Select Document > Export > Document Groups. Select a location for saving the Excel file. Accept the default name or change it. Select Save.
tip
If you use the naming convention for document groups as shown above, then the table shows the more conventional format with attributes / variables as column header and the various values for each variable in the table cells.
Importing Document Groups from Excel
If you want to prepare a table for import, the easiest way is to export a table first. This way you generate a table that already contains all document names in the order as they occur in ATLAS.ti
Export a document group table (see above).
Add the document attributes as column headers. * If there are multiple values for an attribute, add the prefix ´#´. * If you do not add a prefix, a document is assigned to the group if the cell value is 1.
Enter the values for each document in the table cells.
-
if there is no entry in a cell, the document is not assigned to a group.
-
if two or more values of the same attribute apply to the document, then enter the values separated by a coma.
In the following you see two examples:
| Document Name | #gender | #age group | likes chocolate | #favourite drink |
|---|---|---|---|---|
| doc 1 | male | 1 | 1 | cola |
| doc 2 | female | 2 | milk,beer | |
| doc 3 | female | 2 | 1 | juice |
| doc 4 | male | 1 | tea, coffee, cola | |
| doc 5 | male | 3 | 1 | coffee |
Save the table in Excel.
Example Excel table ready for import to ATLAS.ti:

Importing the Table
Close the table in Excel before importing.
inst
Select Document > Import > Document Groups. Select the Excel file and click Open.
tip
If you want to add new groups even though a few groups already exist, you can proceed as described. Just leave existing groups in the table. ATLAS.ti will recognize them and does not create them anew.
Working with Quotations
Video Tutorial: Working with Quotations
Interview with Christine Silver, expert in Computer Assisted Qualitative Data Analysis Software).
"When you create a quotation, you’re marking a segment of data that can later be retrieved and reviewed. You might know, right at that point how and why it’s interesting or meaningful, in which case you can immediately capture that – by re-naming it, commenting on it, coding it, linking it to e.g. another quotation, or a memo. If you don’t yet know, you can just create the quotation, and come back and think about it later, perhaps when you have a better overview of the data set in its entirety and are ready to conceptualise meaning in relation to your research objectives."
"One of my favourite things about ATLAS.ti is that quotations can be visualised and worked with in a graphical window, i.e., the ATLAS.ti networks. The content of quotations can be seen within the network, and quotations can be linked, commented upon, and coded in that visual space. This is very useful if you like to work visually or are used to analysing qualitative data manually with highlighters, white-boards, post-it notes etc. Networks can also be used as visual interrogation spaces – for example to review quotations which have more than one code attached, which is very powerful. Everything you do in the network is connected throughout the ATLAS.ti project."
The ATLAS.ti Quotation Level
The ATLAS.ti quotation level gives you an extra layer of analysis. In ATLAS.ti you are not required to immediately code your data as in most other QDA software. You can first go through your data and set quotations, summarize the quotations in the quotation name and write an interpretation in the comment field. This is useful for many interpretive analysis approach for the process of developing concepts. Once you have ideas for concepts you can begin to code your idea. This also prevents you from falling into the coding trap, i.e. generating too many codes. Codes that can be applied to only one or two segments in your data are not very useful. Code names should be sufficiently abstract so that you can apply them to more than just a few quotations.
You will also see later in the analysis process that you find that none of the further analysis tools like the Code Document Table or the Code Co-occurrence Talbe seem to be very useful.
If you find yourself generating 1000 or more codes, take a look what you can do with quotations instead. Based on that develop codes on a more abstract level allowing you to build a well rounded code system.
Creating Quotations in Text Documents
When you code data, quotations are created automatically. See Coding Data.You can however also create quotations without coding. To do so:
Highlight a section in your text, right click and select the option Create Quotation. Alternatively, you can also use the shortcut cmd+H.

Once a quotation is created, you see a blue bar in the margin area and an entry in the Quotation Manager and the Document tree in the Project Explorer.
Modifying Quotation Boundaries
Modifying the length of a quotation is easy.
If you select a quotation, e.g. by clicking on the bar in the margin area, you see a blue line with a dot at the beginning and at the end of the quotation. Move the start or end position to a different location depending on whether you want to shorten or lengthen the quotation. This applies to all media types.

Quotation ID and Reference
Each quotation has an ID, which consists of two numbers:
 The ID 2:15 for example means that the quotation comes from document 2, and it is the 15th quotation that was created in this document. It is located in the 10th paragraph. Quotation 6:1 comes from document 6; it is the first quotation created in document 6 and can be found in paragraph 67-71.
Quotations are numbered in chronological and not in sequential order. If you want to change this order, see Working with Quotations.
The ID 2:15 for example means that the quotation comes from document 2, and it is the 15th quotation that was created in this document. It is located in the 10th paragraph. Quotation 6:1 comes from document 6; it is the first quotation created in document 6 and can be found in paragraph 67-71.
Quotations are numbered in chronological and not in sequential order. If you want to change this order, see Working with Quotations.
Adding Quotation Names and Writing Comments
Being able to name each quotation has a number of useful applications.
- It allows you to quickly glance through your quotations in list view.
- You can use the name field to paraphrase a quotation as required by some content analysis approaches, or to write a short summary.
- You can use the name field for fine-grained coding (line-by-line Grounded Theory coding; initial coding in Constructive Grounded Theory, or as required by other interpretative approaches) instead of applying codes. If you already apply codes during this phase, you will end up with too many codes that are useless for further analysis. See Building a Code System.
- Adding titles to multimedia quotations. Seee Working with Multimedia Data.
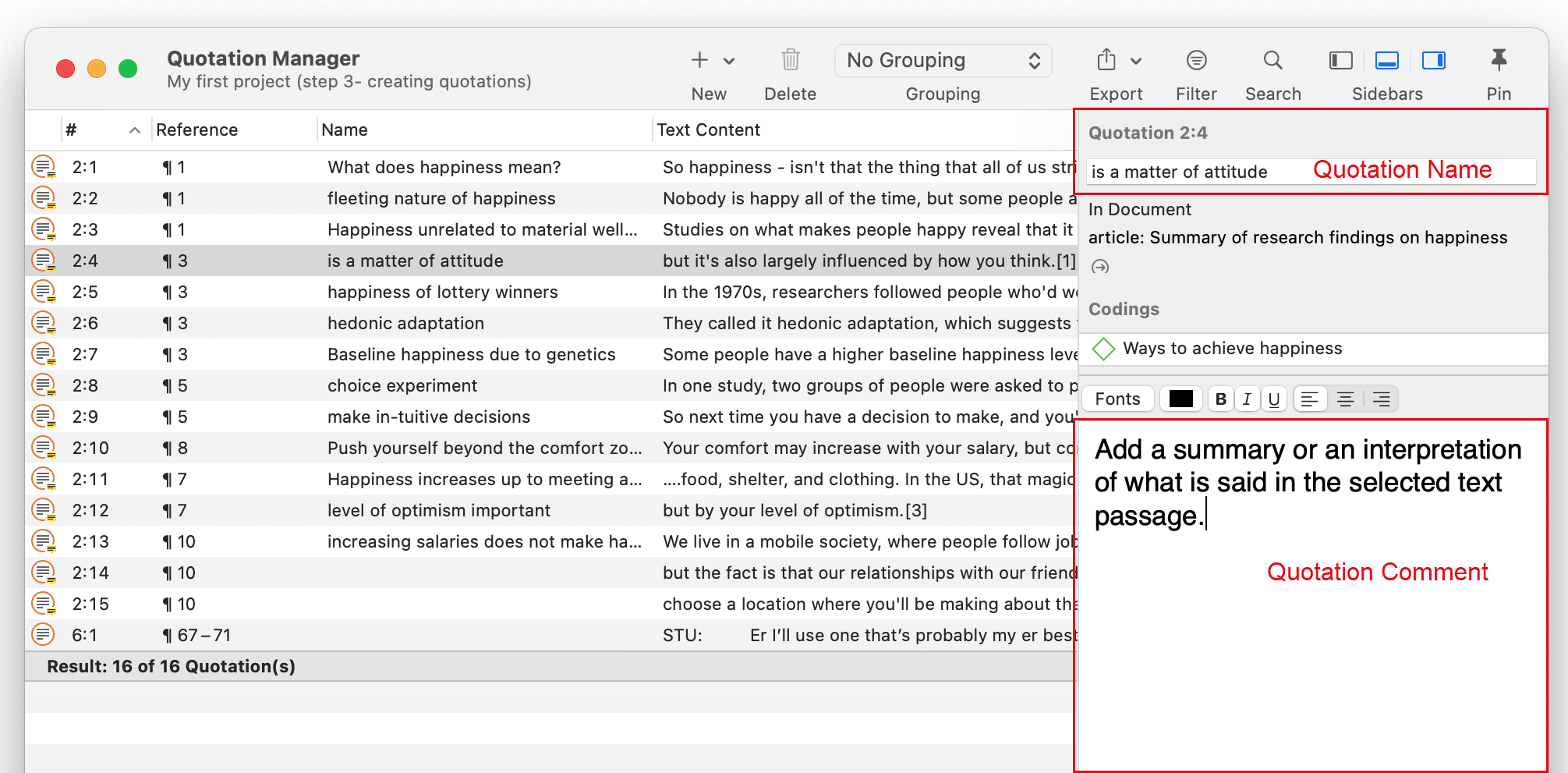
To add a name to a quotation, select it and left-click the name field, or add a text to the name field in the inspector on the right-hand side. You can write furhter infomation about the quotation like a summary or interpretation in the comment field that you also find in the inspector.
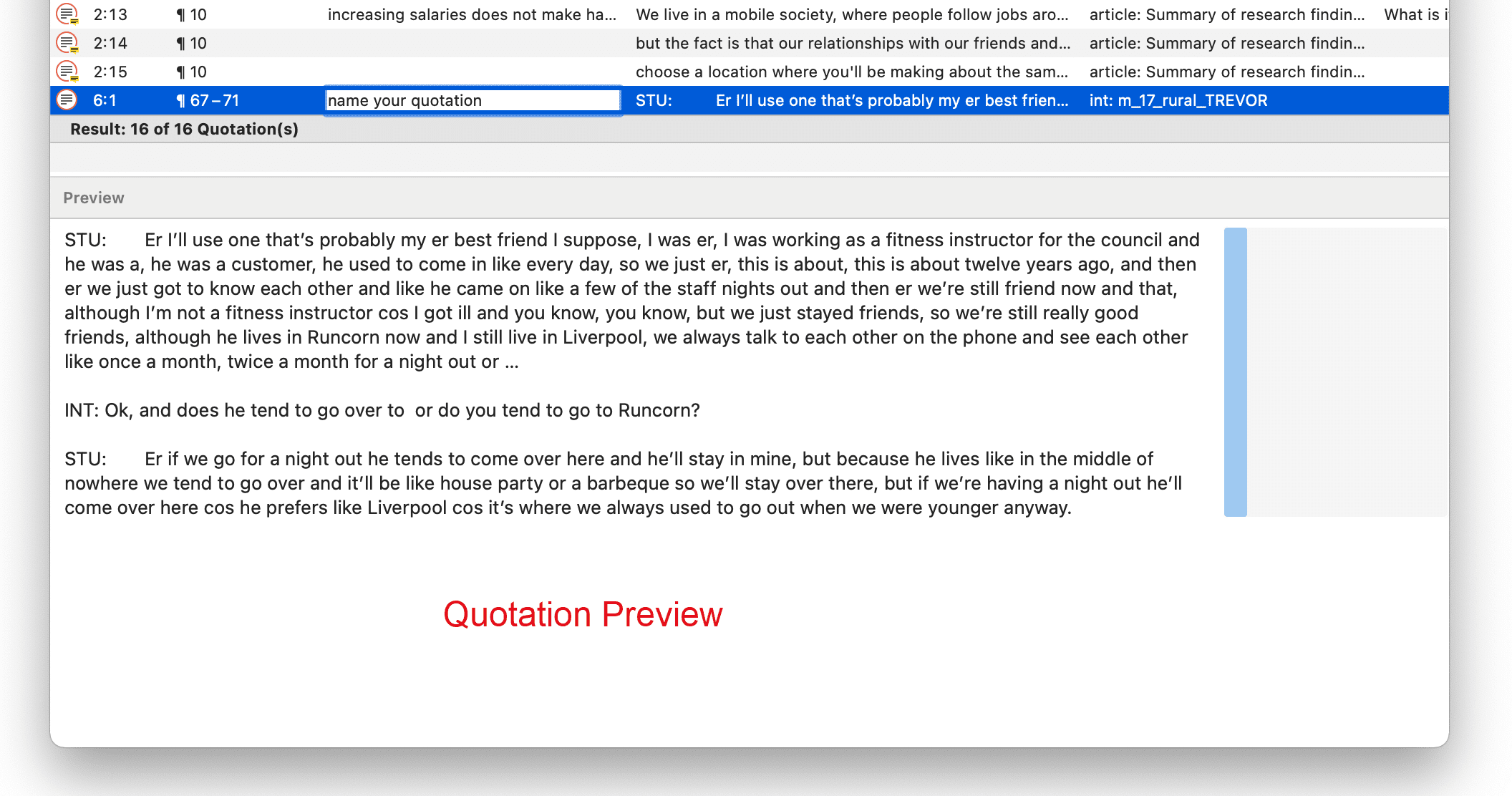
tip
If you select a quotation in the Quotation Manager, you see a preview of the quotation in the panel below the quotation list. This applies to all data file formats.
Coding Data
Video Tutorial: Coding Data
quotation
“Coding means that we attach labels to 'segments of data' that depict what each segment is about. Through coding, we raise analytic questions about our data from […]. Coding distills data, sorts them, and gives us an analytic handle for making comparisons with other segments of data” (Charmaz, 2014:4).
“Coding is the strategy that moves data from diffuse and messy text to organized ideas about what is going on” (Richards and Morse, 2013:167).
"Coding is a core function in ATLAS.ti that lets you “tell” the software where the interesting things are in your data. ... the main goal of categorizing your data is to tag things to define or organize them. In the process of categorization, we compare data segments and look for similarities. All similar elements can be grouped under the same name. By naming something, we conceptualize and frame it at the same time" (Friese, 2019).
Creating New Codes without Coding
You can create codes that have not (yet) been used for coding. Such codes are called "free" codes. This can for example be useful when ideas for codes come to mind during normal coding work and that cannot be applied to the current segment but will be useful later. Sometimes you also need free codes for expression conceptual connections in networks. If you already have a list of codes, possibly including code descriptions and groupings elsewhere, you can use the option: Importing A List Of Codes.
Click on the Code button in the toolbar and select New Code(s) from the drop-down menu. The short-cut key combination is Cmd+K.
You can also create new codes in the Code Manager by clicking on the + button.
Coding with a
Open a document and highlight a data segment, i.e., a piece of text, audio or video data, a rectangular area in a graphic document, or a location in a geo document.
inst
Right-click and select Apply Codes, or use the short-cut Cmd+J, or click on the 'Apply Codes' button in the toolbar.

Enter a name and click on the plus button or press enter.
 You can continue to add more codes, or simply continue to select another data segment. The dialogue closes automatically.
You can continue to add more codes, or simply continue to select another data segment. The dialogue closes automatically.
for more information on working with data other than text, see Working With Multimedia Data and Working With Geo Docs.
Display of Coded Data Segments in the Margin Area
The coded segment is displayed in the margin area. A blue bar marks the size of the coded segment (= quotation), and the code name appears next to it. When coding data in this way, a new quotation is created automatically, and the code is linked to this quotation.

Display of Codes in the Project Explorer and Code Browser
In the Project Explorer under the main Codes branch, all codes are listed. If you only want to see the list of codes, click on the code icon in the toolbar.
The number behind a code, e.g., (23) means that the code has been applied 23 times.
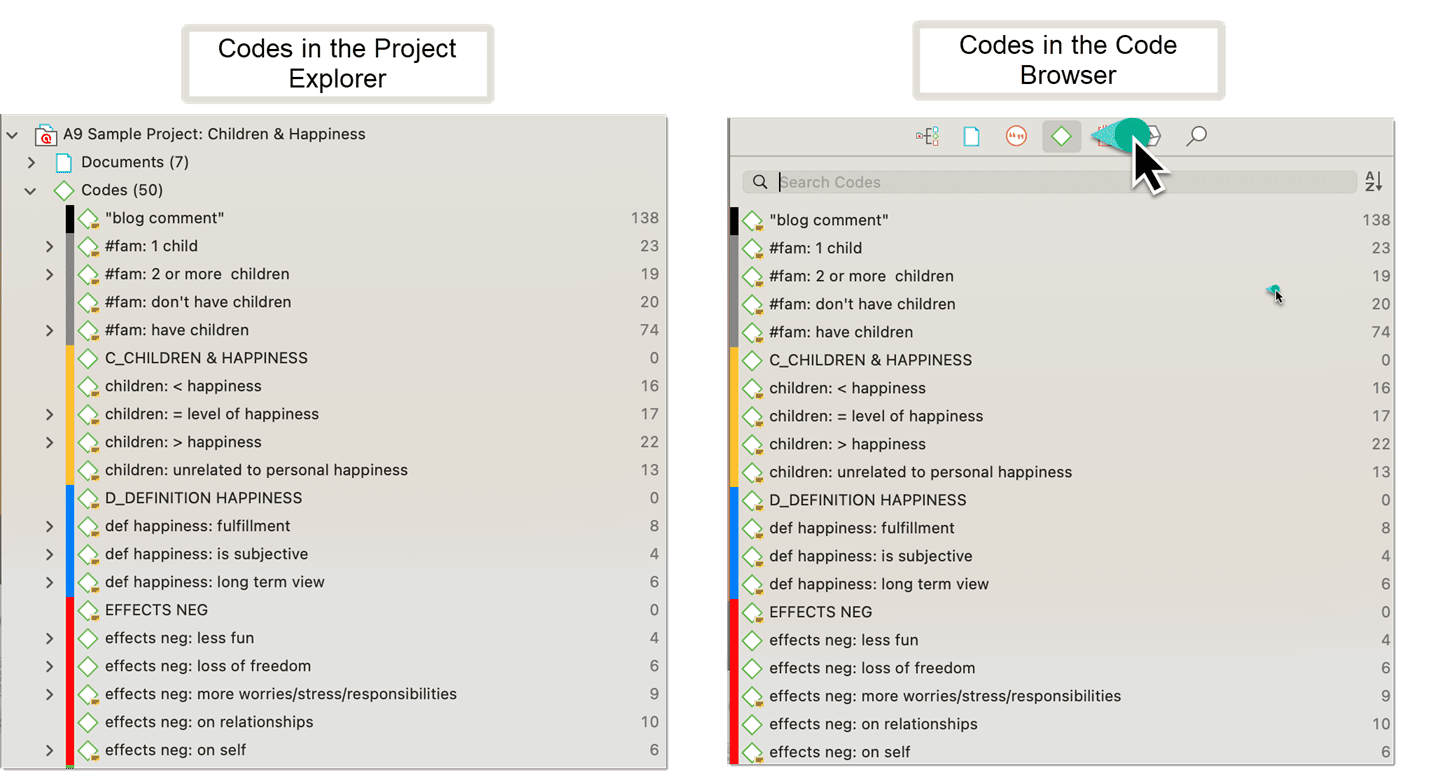
If codes are linked to other codes, you can expand the code subtree further. This is not a hierarchical display of codes. Linkages you create between codes are usually of a conceptual nature and can be directed and non-directed links. For more information see: About Links and Nodes.
The following video tutorial shows more about the meaning and purpose of linking codes in ATLAS.ti: Did you ever wonder what's behind the ATLAS.ti network function.
Display of Codes on the Code Manager
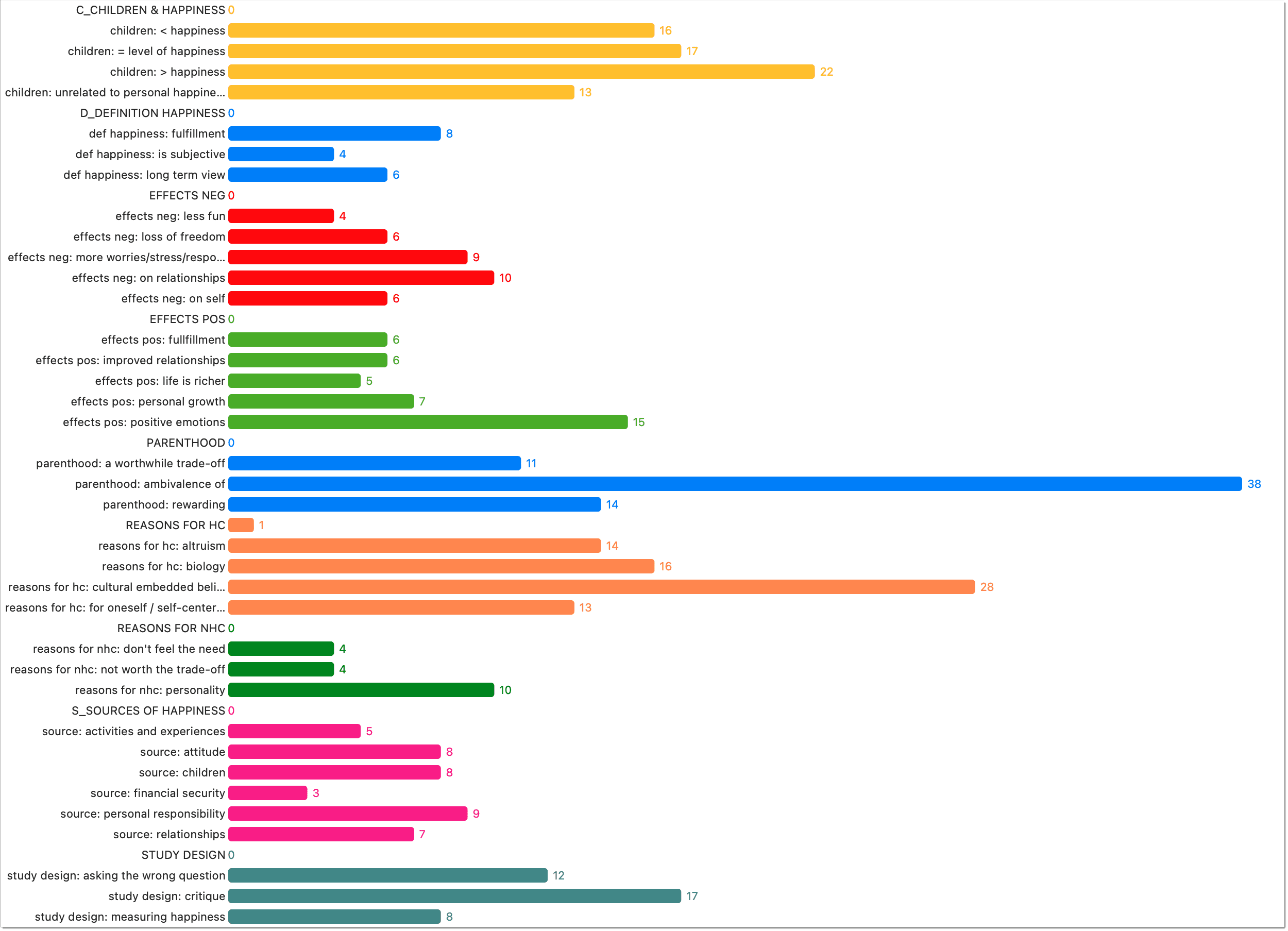
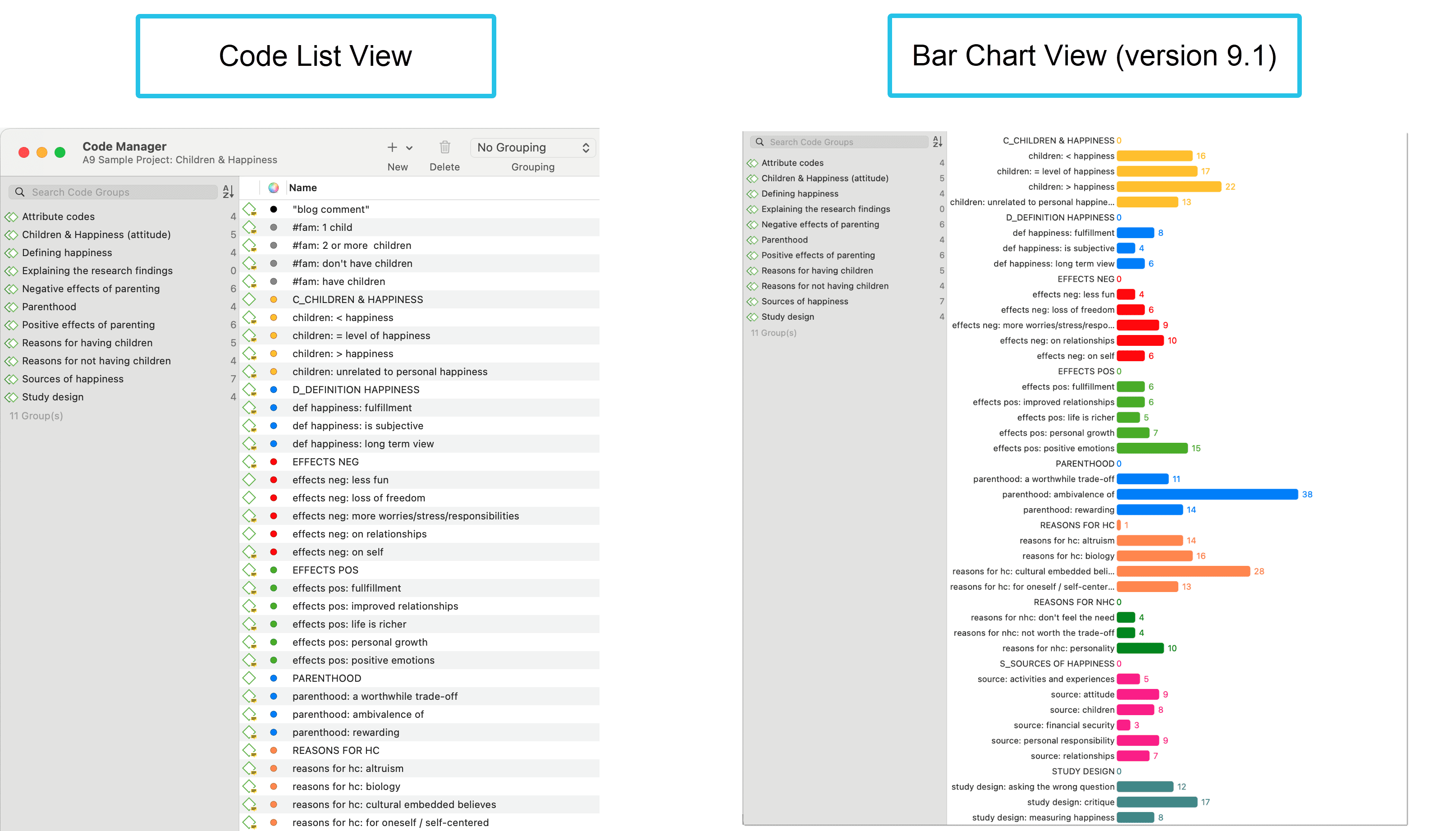
There are three View Modes: You can view codes in list view (default), as cloud or in form of a bar chart:

Code List as Bar Chart
Select the Bar Chart to visualize your code list in form of a bar chart.
The codes in the bar chart view also have a context menu. Thus, also from here, you can start the same actions as in the standard view.
Code Cloud
Select the Cloud option to visualize your code list in form of a word cloud:

If you right-click on a code, the same context menu opens as in 'List' view. Thus, in the cloud view you can start the same actions as in the regular view. You can for instance rename codes, set a color, split codes, or open a network on one or multiple codes.
Applying Existing Codes
Existing codes can be applied using the Coding Dialogue or via Drag & Drop.
Using the Coding Dialogue
Highlight a data segment, right-click and select Apply Codes.
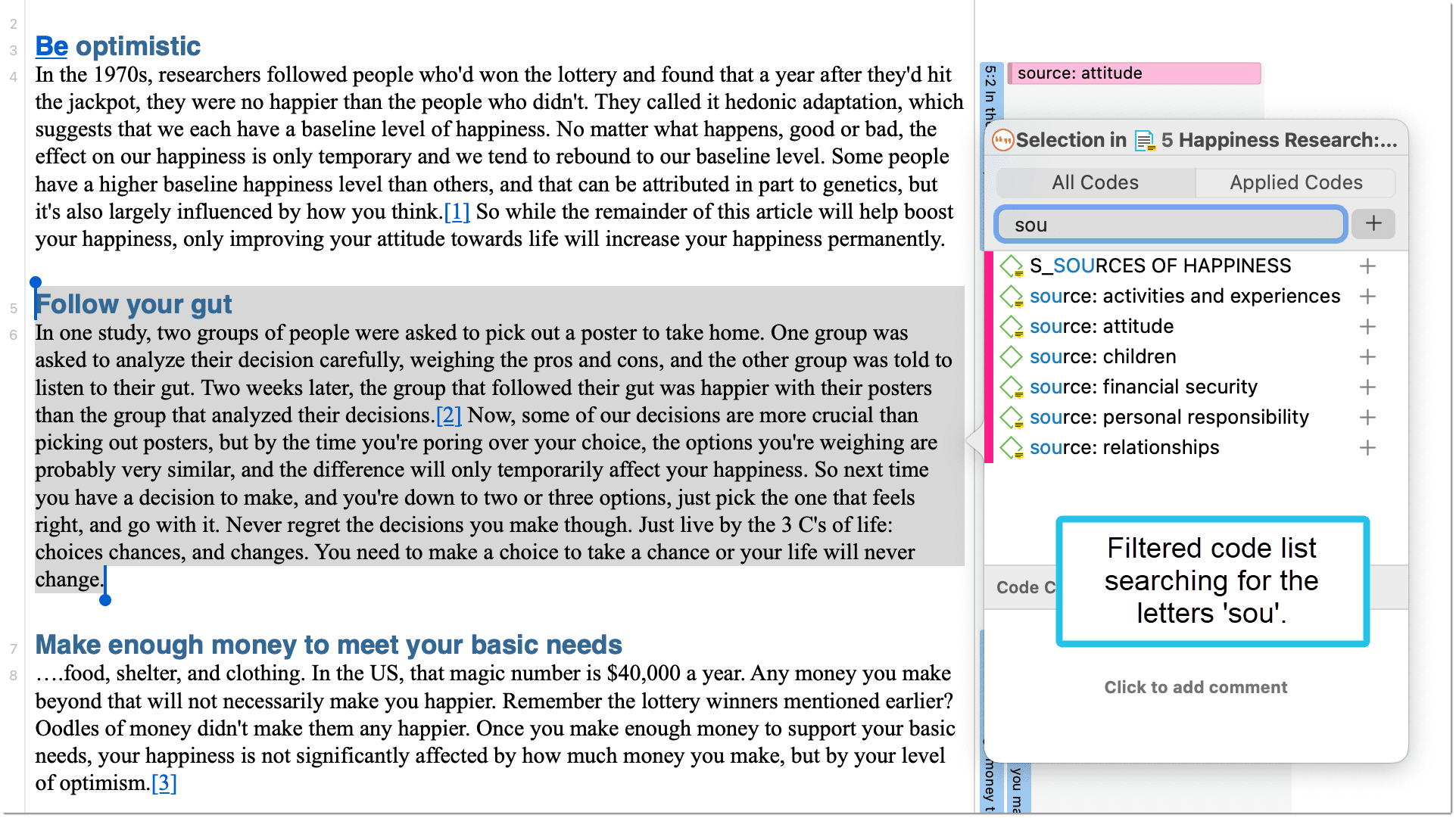
inst
Select one of the existing codes, click on the plus button or press Enter. If you type the first few letters in the entry field, only those codes are presented that match the letter combination.
Code density is not a value that is calculated by the software. It goes up, when the researcher begins to link codes to each other. See Working With Networks.
Drag-and-Drop Coding
Drag-and-Drop Coding is possible from the following locations:
- the Codes branch from the Project Explorer
- the Code Browser in the navigation panel.
- the Code Manager
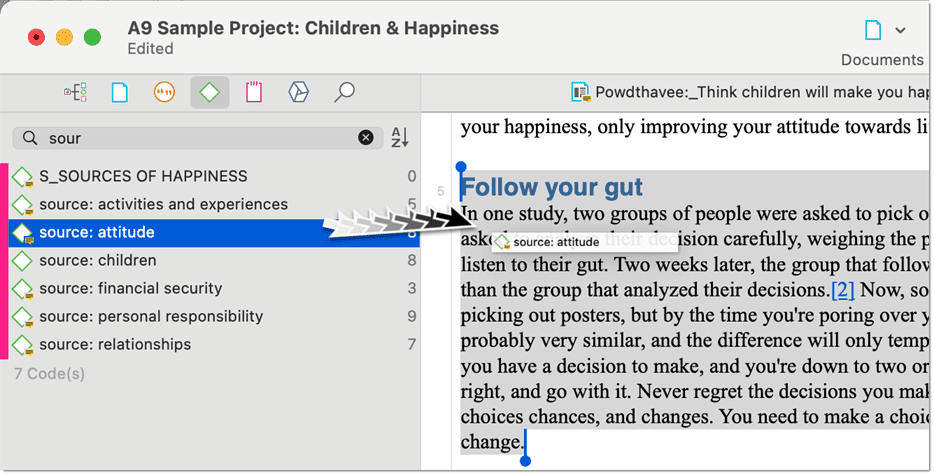
Below you find more Drag-and-Drop options.
To use drag-and-drop coding highlight a data segment, select one or more codes in the above mentioned lists or windows and drag the code onto the highlighted data segment.
Code Browser in the navigation panel: To open the Code Browser, click on the Codes icon. The search field in the Code Browser facilitates handling a longer code list. Rather than scrolling the list, you enter the first letters of a code. Code Manager: When using the Code Manager, it is recommended to place it next to the text you are coding. If you click on the pin on the top right-hand side of the window, the Code Manager stays on top.
You can quickly access codes using code groups to filter the list, or using the search field.
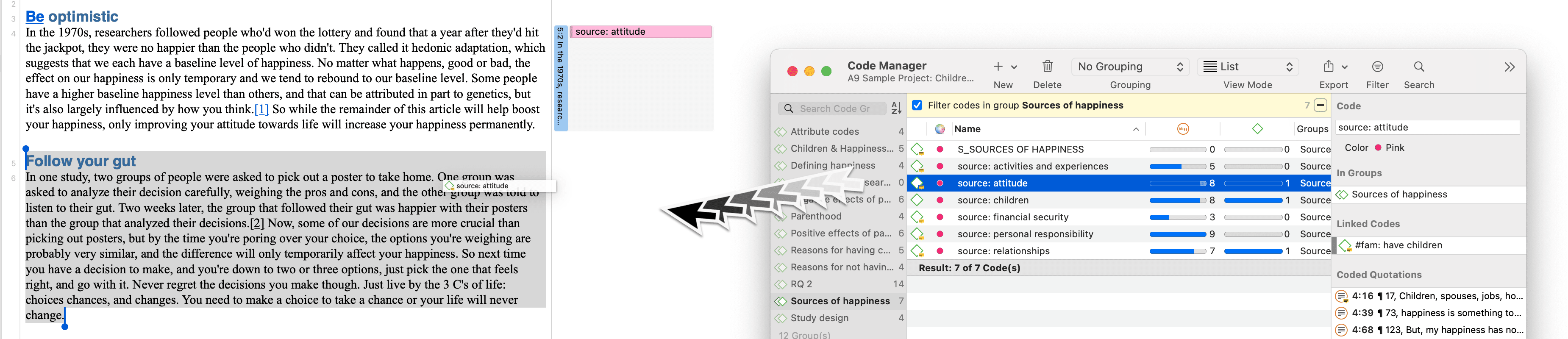
Add Last Used Codes
Applying the last used code(s) to the current data segment is an efficient method for the consecutive coding of segments.
Highlight a data segment or click on an existing quotation.

Right click and select Add Last Used Codes from the context menu.
Keyboard Shortcuts F
| Coding | Short-Cut |
|---|---|
| Create Free Code | Cmd+K |
| Apply Codes | Cmd+J |
| Apply Last Used Codes | Cmd+L |
| Code In-Vivo | Shift+Cmd+V |
Working with Codes
Video Tutorial: Coding Data
Modifying the Length of a Coded Segment
Select the quotation by clicking on the quotation bar or code in the margin area and move the handle in form of a blue line and dot to the right, to the left, or up or down, depending on whether you want to shorten or lengthen the quotation.

Removing a Coding
This option is the reverse function of coding. It removes the links between codes and quotations. Unlike the delete function, neither codes nor quotations are removed; only the association between the code and the quotation is removed.
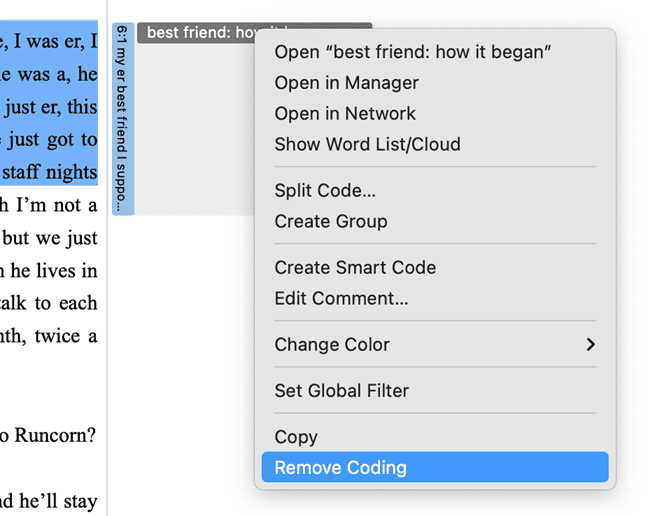
Removing a Coding in the Margin Area
Right-click on the code in the margin area and select the option Unlink from the context menu.
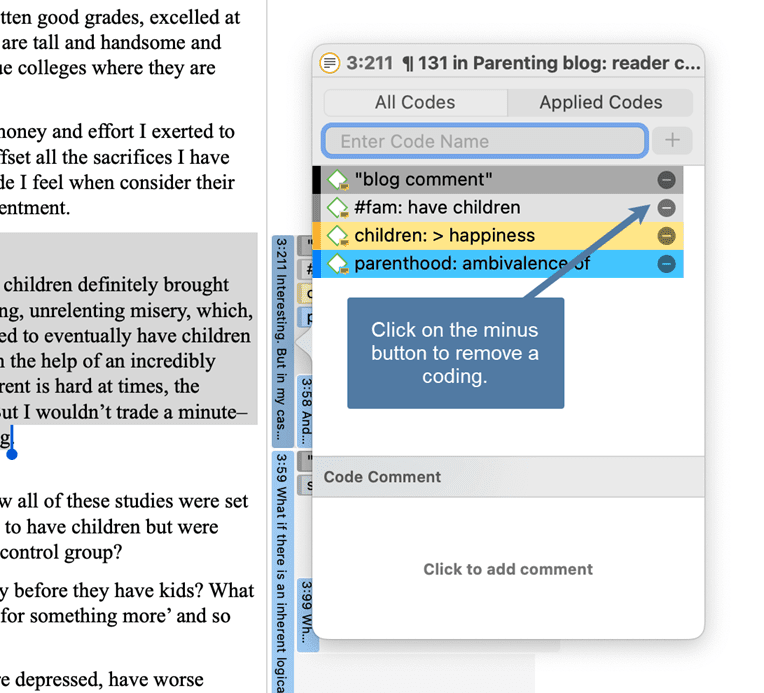
Removing a Coding in the Coding Dialogue
Double-click on quotation in the margin area. This opens the Coding Dialogue. Click on Applied Codes to quickly see which codes have been applied to the quotation. Click on the button with the minus (-) to remove a code.
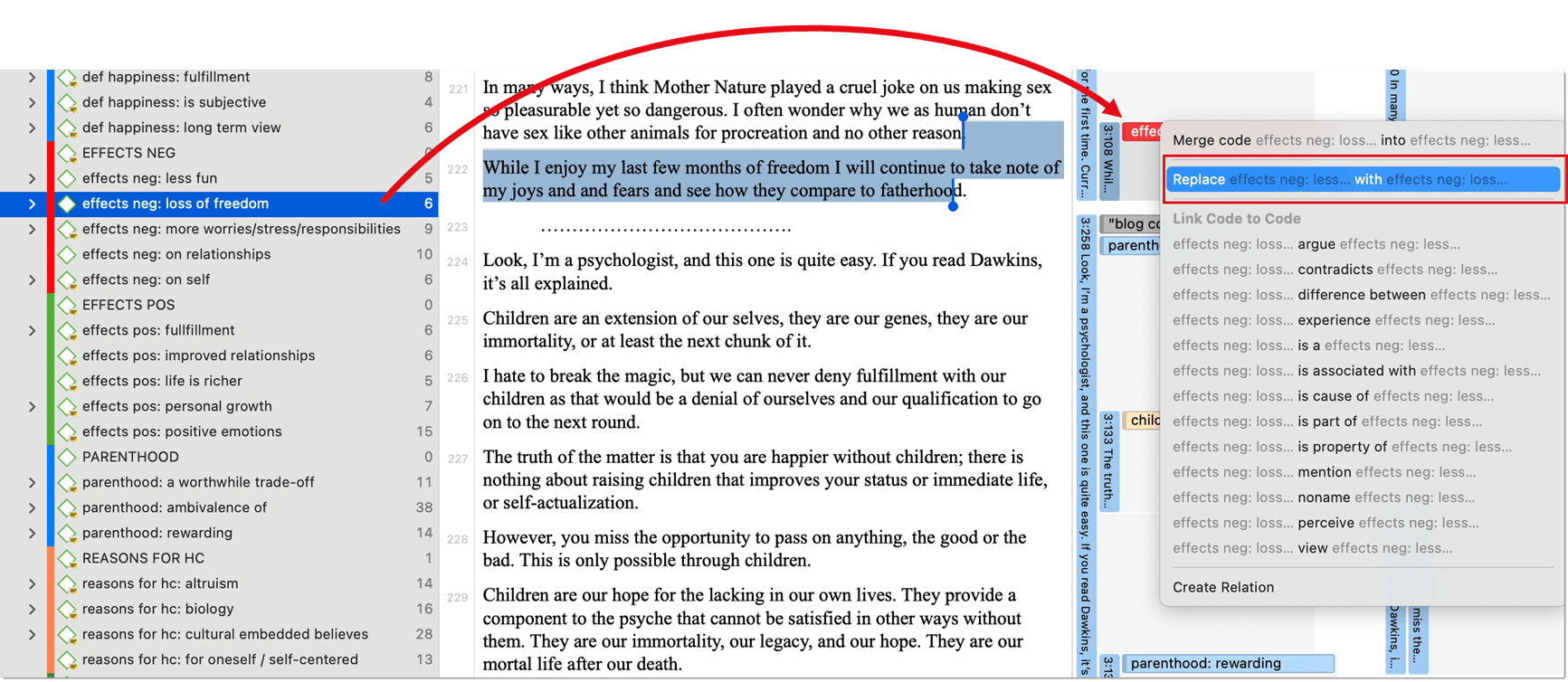
Replacing a Code via Drag & Drop
If you want to replace a code that is linked to a data segment, you can drag and drop another code from either the Project Explorer, Code Browser, or the Code Manager on top of it. When you drop it on top of another code, select the second option from the context menu: Replace ... with ...
Adding, Changing and Removing Code Color
In the Project Explorer, Code Browser, Code Manager, or in a Network right click and select the option Change Color from the context menu.
In the Code Manager or Inspector, select a code and click on the circle.
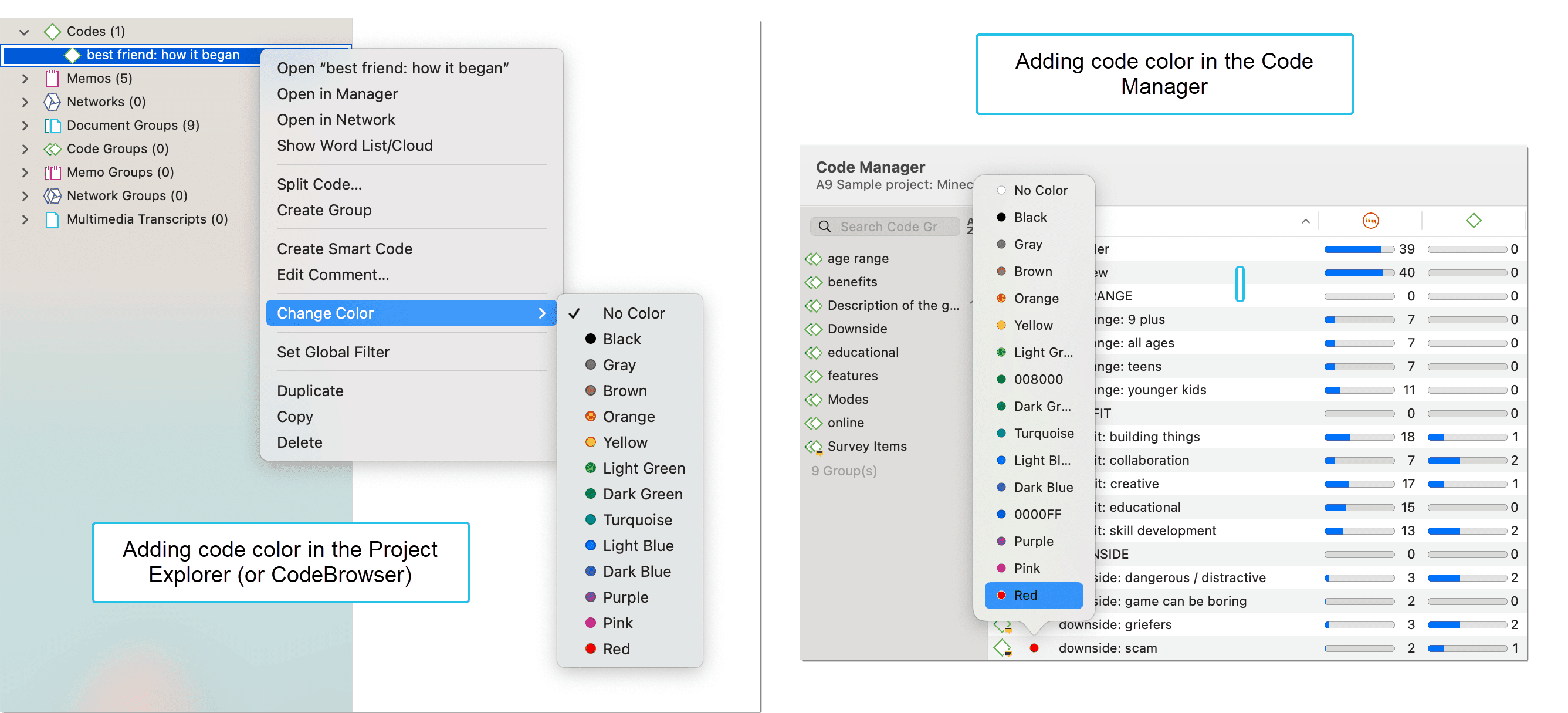
In the image above on the left-hand side you see the default colors. This is a selection of colors from a color palette, which is suitable also for color blind people. In the code list on the right-hand side, you see additional colors. Additional colors can be added if you import a list of codes from Excel. See Importing code lists.
Renaming a Code
You can left-click on a code anywhere to rename a code in in-place edit mode. Another option is to rename the code in the inspector.
Deleting One or Multiple Code(s)
In the Project Explorer, the Code Browser, or Code Manager, right-click on a code and select Delete. To select multiple codes, hold down the command key.
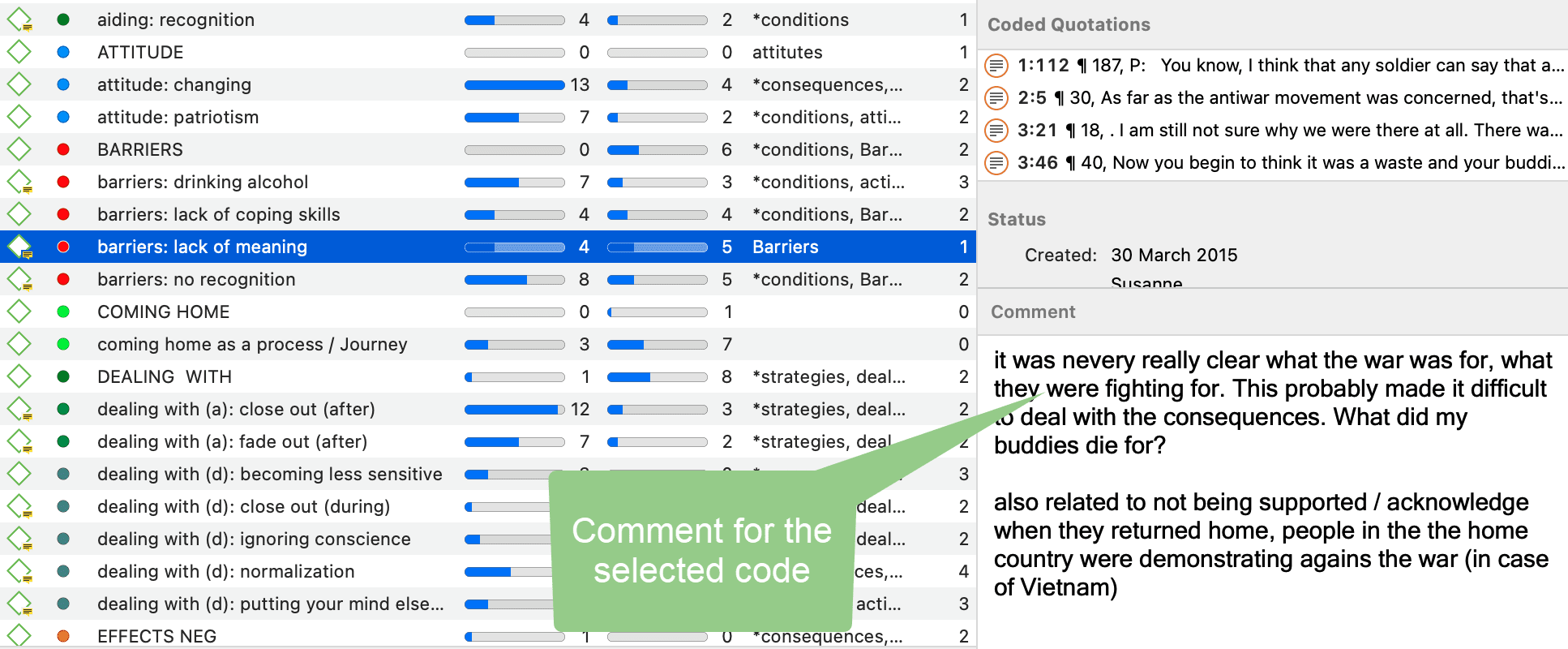
Writing Code Comments
Code comments can be used for various types of purposes. The most common usage is to use them for a code definition. If you work in teams, you may also want to add a coding rule, or an example quote. If you work inductively, you can use code comments to write down first ideas of how you want to apply this code. You can also use it to write up summaries of all segments coded with this code and your interpretation about it. There are several ways to write a code comment.
-
If you select a code anywhere, you can write a code comment in the inspector.
-
In the margin area, you can double-click on a code to open the comment editor. Another option is to right-click on a code and select the Edit Comment option from the context menu.
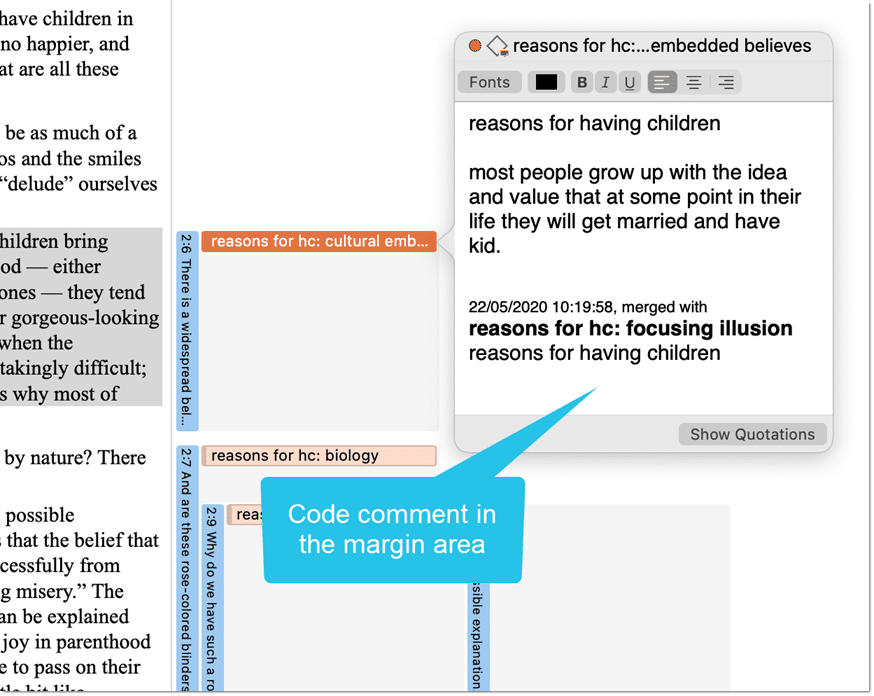
All codes that have a comment shows a little yellow flag.
Creating a Code Book
The recommended option to create a code book is to use the Excel export option in the Code Manager:
Open the Code Manager, select all codes (e.g. Cmd+A), click on the Export button and select Export as Spreadsheet.
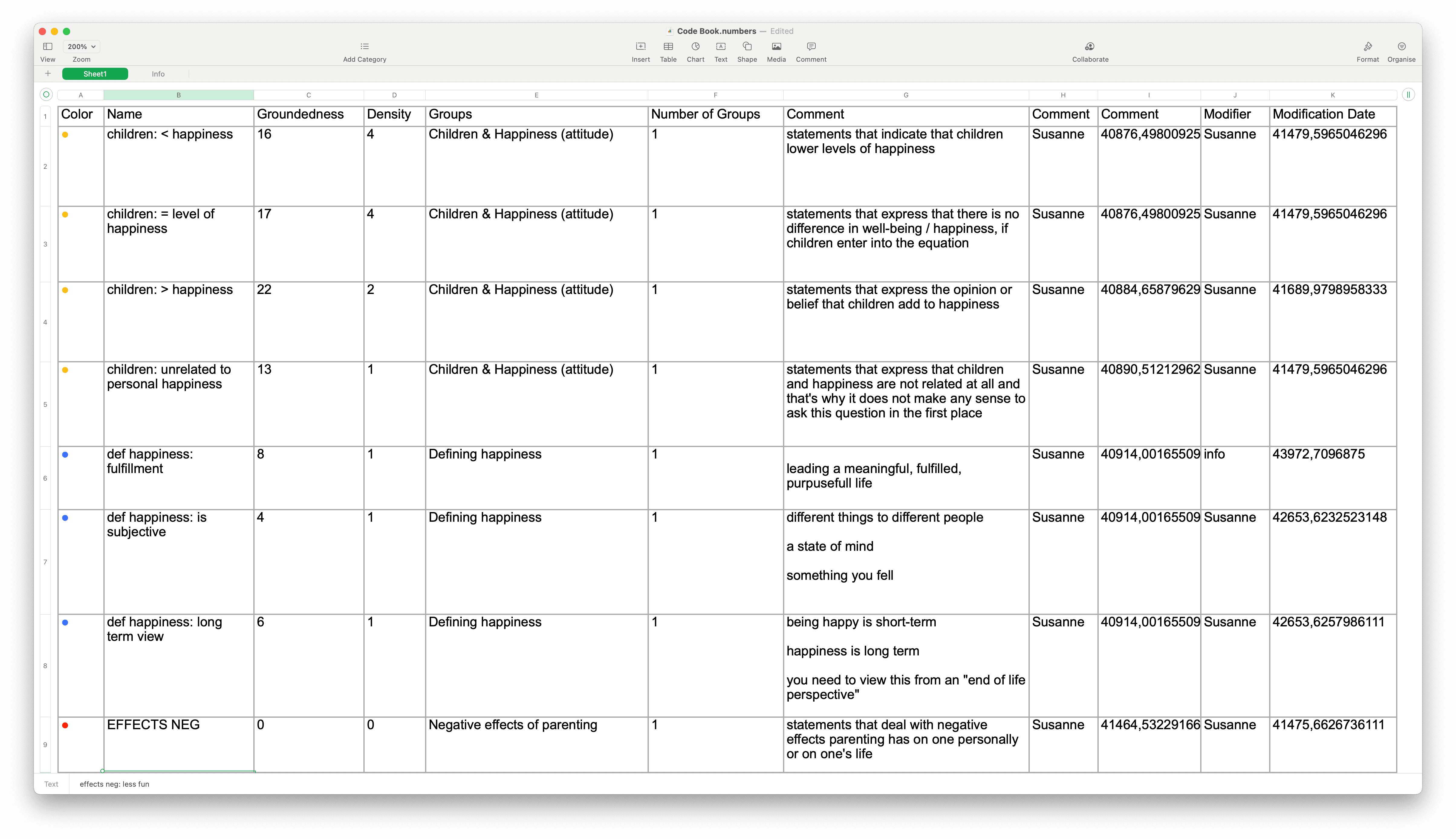
ATLAS.ti exports are columns that are visible in the Code Manager. If you click on a column header, you can deselect columns that you do not want to export.

Merging Codes
Video Tutorial: Merging Codes
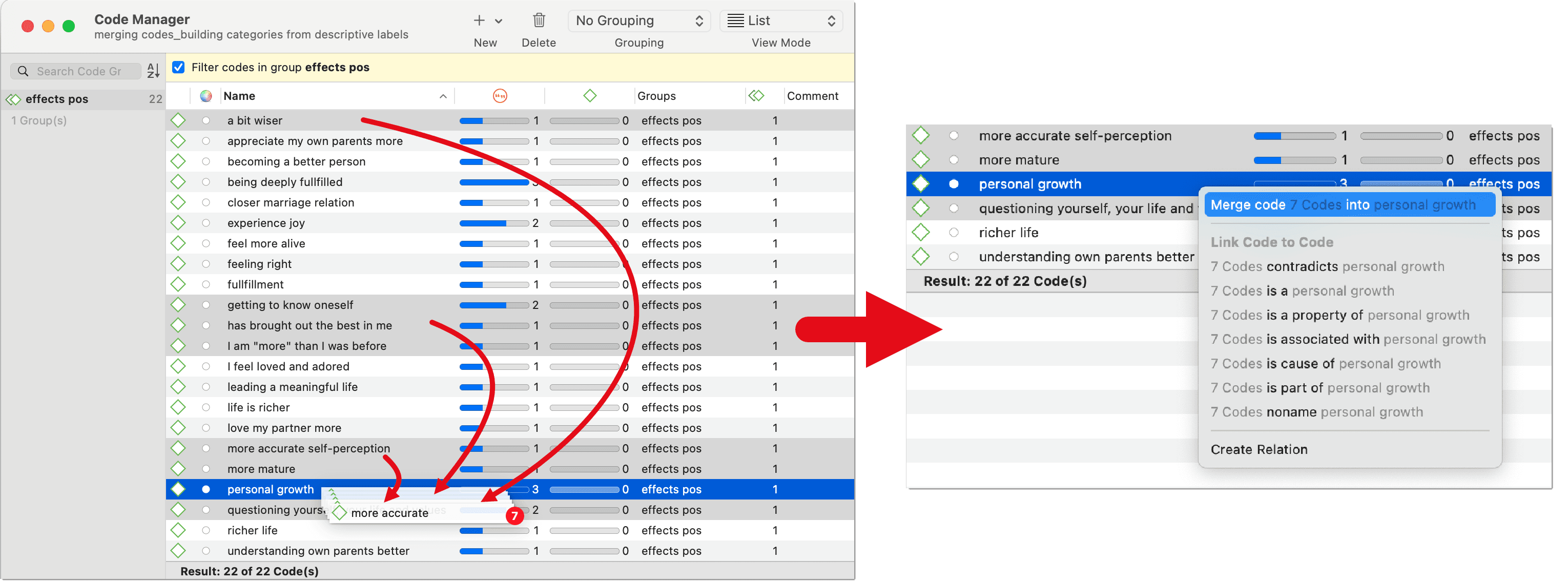
You may begin your coding very close to the data generating lots of codes. In order not to drown in a long list of codes, you need to aggregate those codes from time to time, which means merging and renaming them to reflect the higher abstract level. Another reason for merging is that you realize that two codes have the same meaning, but you have used different labels.
Select two or more codes in the Code Manager and drag them to the code where you want to merge them into. A menu opens. Select the first option Merge code ... into ...
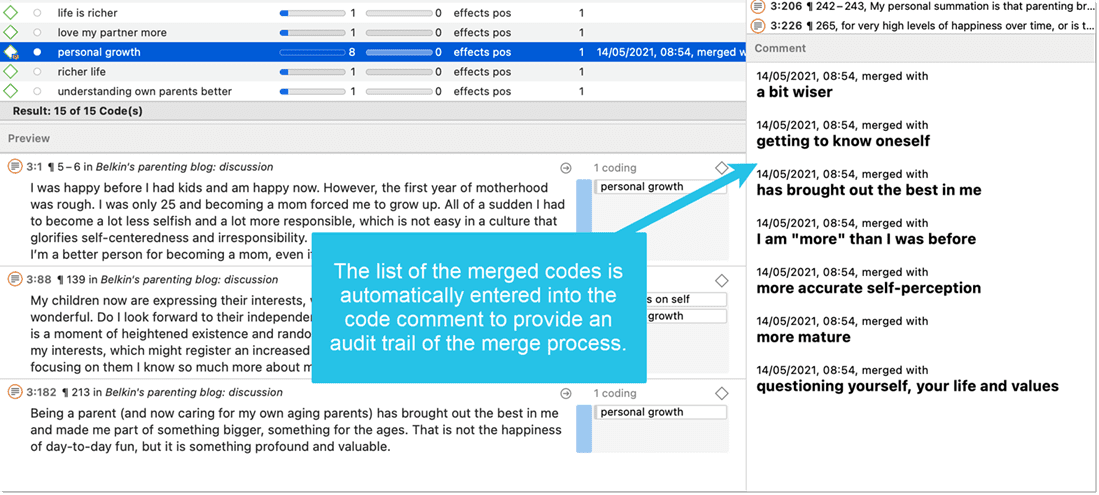
A comment is automatically inserted into the target code that provides an audit trail of which codes have been merged. If the codes that are merged had a comment, these comments are also added to the target code.
Splitting a Code
Video Tutorial: Splitting Codes
Splitting a code is necessary if you have been lumping together many quotations under a broad theme. This is a suitable approach for a first run through to get an idea about your data. At some point, however, those codes need to be split up into smaller sub codes.
Right-click a code that you want to split in the Code Manager or Project Explorer and select Split Code from the context menu.
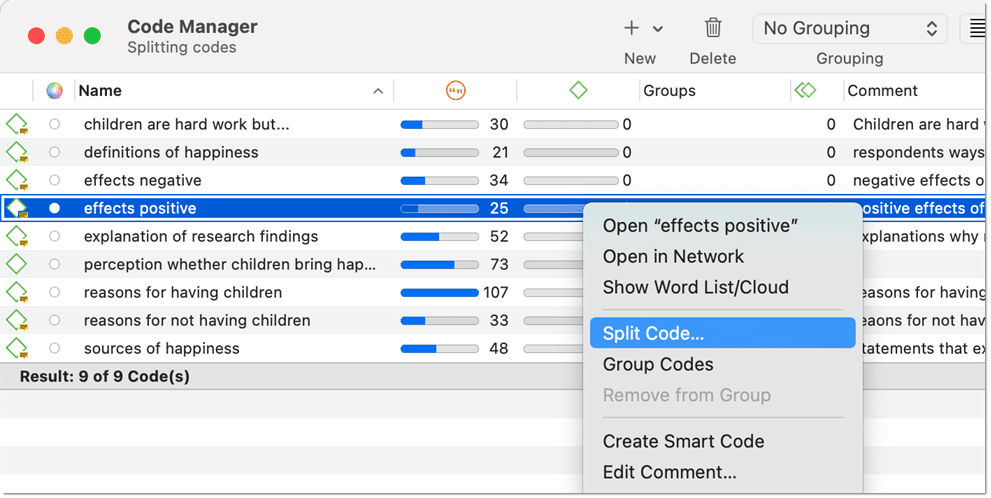 In the Split Code tool, you see the list of the quotations coded with the code.
In the Split Code tool, you see the list of the quotations coded with the code.
Click on the button Add Codes. Enter as many sub codes as you need.
ATLAS.ti automatically creates a prefix that consists of the name of the code you split followed by a colon (:). After adding all sub codes that you need, click Add.
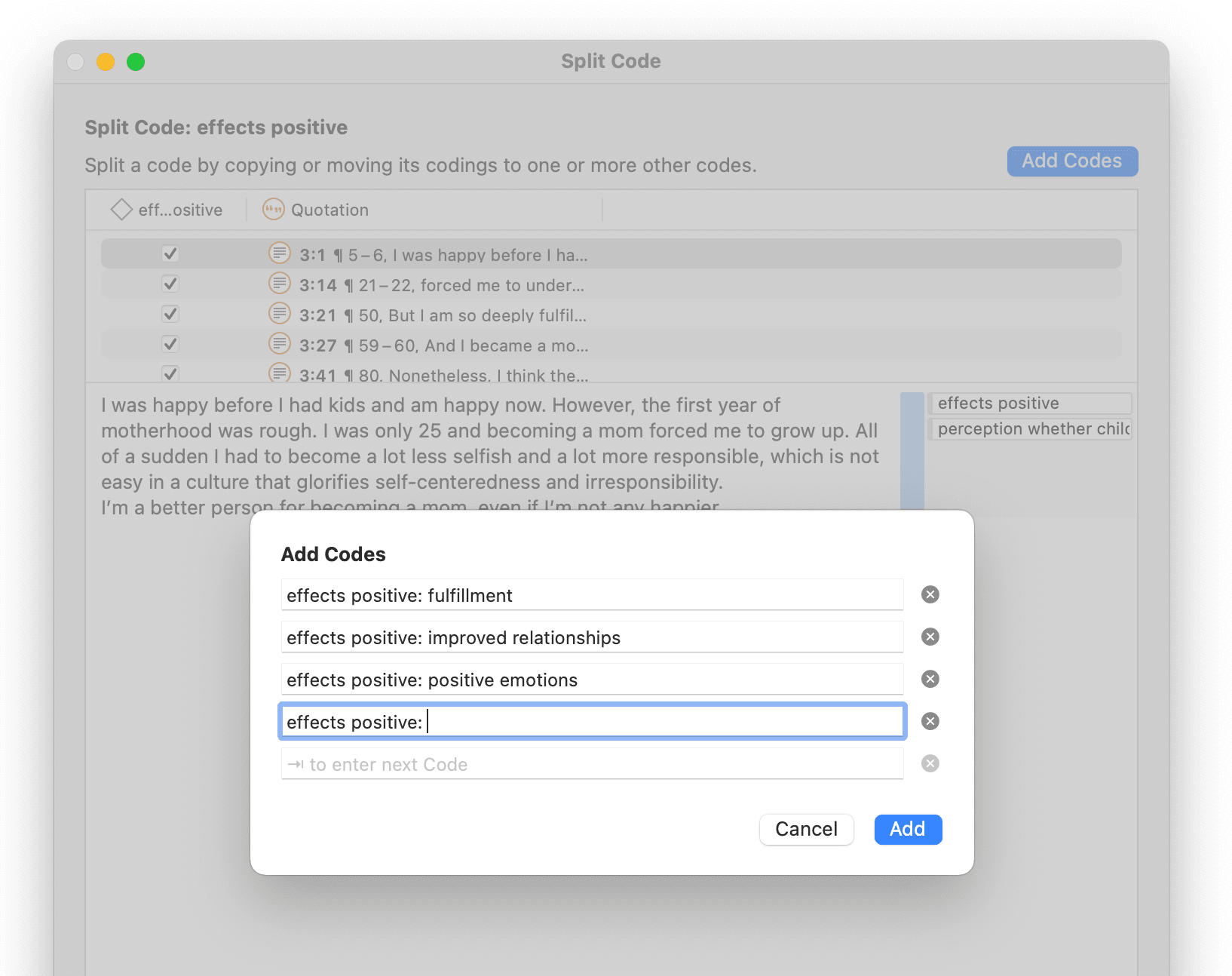
You can now assign the quotations to one or more sub codes. When you select a quotation, its content is shown below the list of quotation. Assign the quotations by clicking on the checkbox of the sub codes that apply. The quotation is automatically unlinked from the main code that you are splitting.
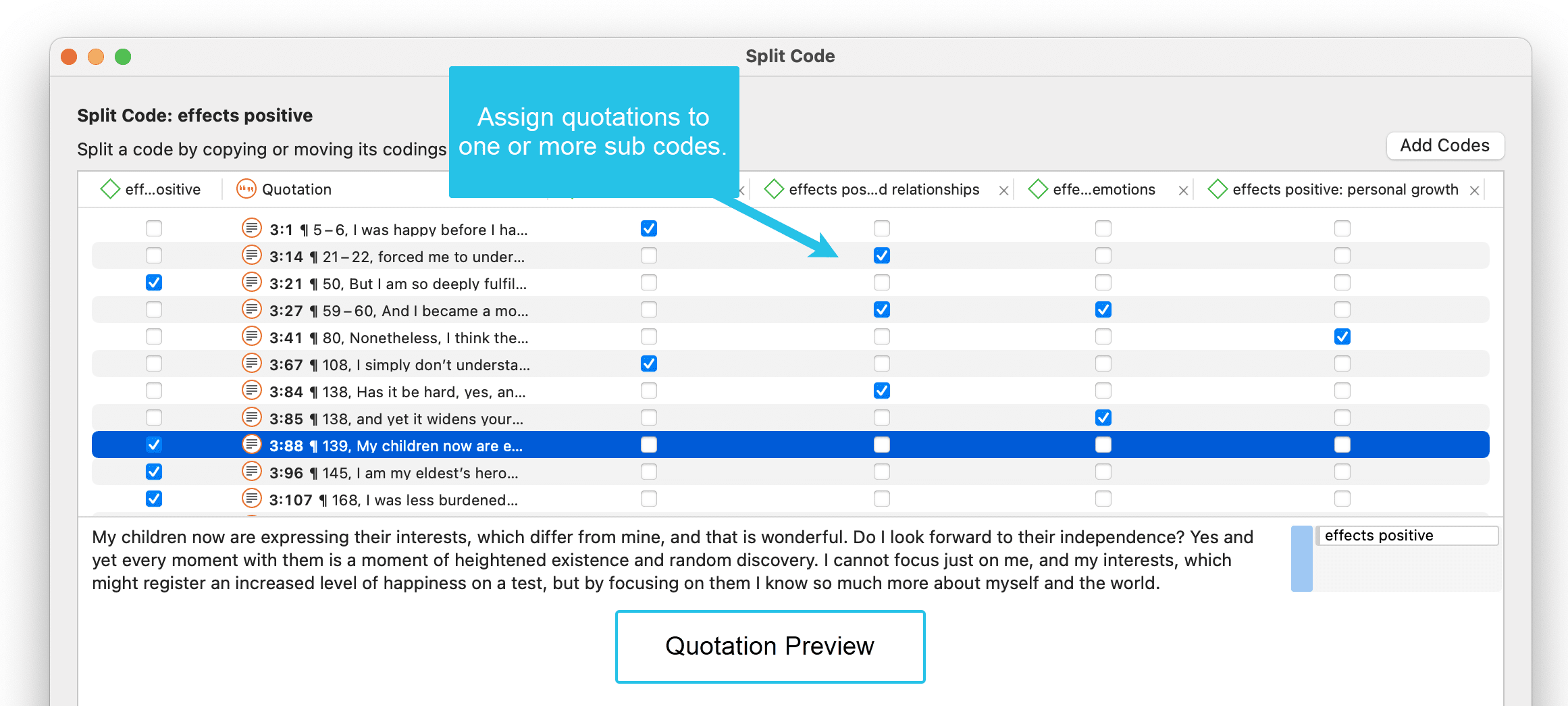
After you have distributed some or all of the quotations into sub codes, click on Split Code. Now the sub codes are created, and the quotations are assigned accordingly.
It is not required that you assign all quotations to sub codes. If you are not sure what to do with a quotation, you can leave it coded with the main code and split it later.
It is recommended not to double-code with the main, and the sub code. It takes up unnecessary space in the margin area. Instead, create a code group of all codes that share the same prefix. This way, you can access all data of this category by using the code group as filter.
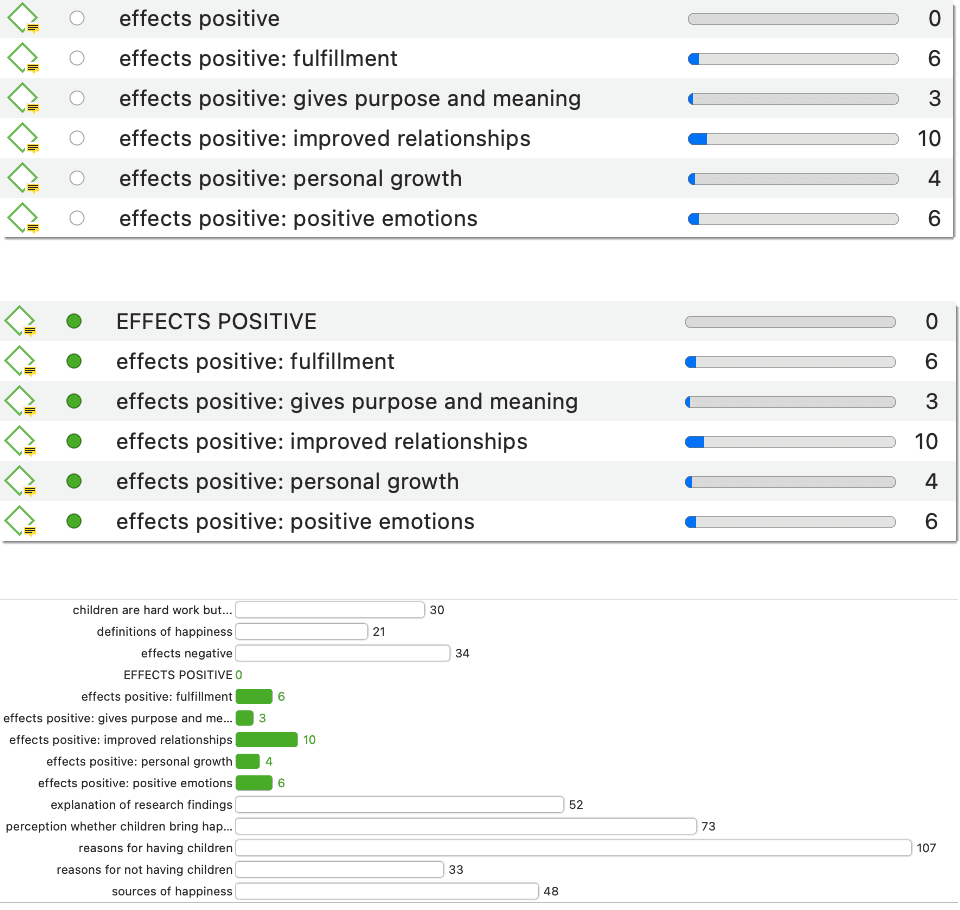
In the image below you see how the split code looks like in the Code Manager. If you keep the code that you split, you can use it as category label. For it to stand out as header, you can rename it using capital letters. Another option is to add a color to the newly formed category.
The bar char view also shows the category that was built through splitting the code. The other high frequency codes in the list can be inspected next to develop the code system further.
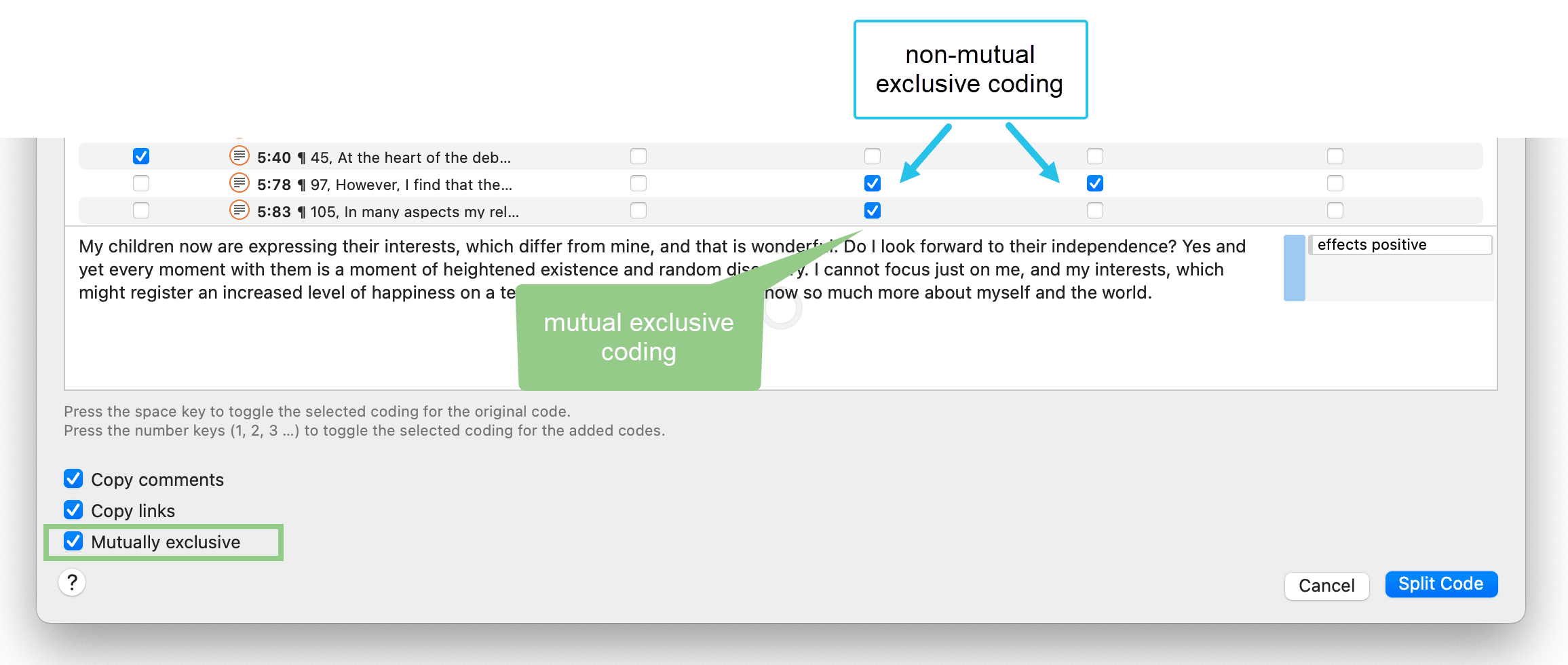
Mutually Exclusive Coding
If you do not want to allow that a quotation is coded with two of the sub codes, activate the option Mutually Exclusive. This is a requirement for some content analysis approaches and for calculating inter-coder agreement. See Requirements for Coding.
Options
-
Copy Comments: Select if you want all sub codes to have the same comment as the code you split.
-
Copy links: Select if you want all sub codes to inherit existing links to other codes or memos.
-
Mutually exclusive: If activated, you can assign a quotation to only one sub code. This is a requirement for some content analysis approaches and for calculating inter-coder agreement.
Building a Code System
A well-structured code list is important for further analysis, where you look for relationships and patterns in the data, with the goal of integrating all results to tell a coherent story. If, as in a survey, you only have questions with the answer categories "yes" and "no" in your questionnaire, your data will only consist of nominal variables. This means that the analysis is limited and does not go beyond the descriptive level. This is like a code list that consists of a set of codes whose analysis level remains indefinite.
Benefits of a well-structured code list
- it creates order
- it brings conceptual clarity for yourself and others
- it provides a prompt to code additional aspects as you continue to code
- it will assist you in identifying patterns
Characteristics of a well-structured code list
- Each code is distinct, its meaning is different from the meaning of any other code.
- The meaning of each code is described in the code comment.
- Each category can be clearly distinguished from other categories.
- All sub codes that belong to a category are similar as they represent the same kind of thing. Nonetheless, each sub code within a category is distinct.
- Each code appears only once in the code system.
- The code system is a-theoretical. This means the code system itself does not represent a model nor a theory. The codes merely describe the data, so that the data can easily be accessed through them.
- The code system should be logical, so you can find what you are looking for.
- The code system contains between 10 and 25 top-level categories.
- The code system has no more than two to three levels. Thus, it consists of categories and sub codes, and possible a dimension like positive / negative, or a time indicator like before / during / after. If dimensions apply to many codes in the code system, it is better to create separate codes and double-code the data with the content code plus the dimension.
Building a Code System
The aim of building a code system is that you can access your data through the codes and that you can make full use of the analysis tools. For example, knowing you can cross-tabulate codes using the code co-occurrence table helps to understand why it is important to code in an overlapping fashion.
You start by creating codes to catch ideas, the list of code grows. You then begin to sort and order codes into categories and sub codes making use of the merge and split functions. It is recommended to develop categories that contain only one level of sub codes (two if necessary). This allows you to flexibly combine different aspects when querying the data, and to avoid unnecessary long code lists and code labels.
You will find that you have different types and levels of codes:
- Structural codes that code speaker units in focus groups
- Attribute codes that code sociodemographic attributes of speakers or persons within a document
- Codes that indicate a category and codes that are sub codes of a category, and so on.
As there is only one entity for all of these different things - the code - you can indicate different types and levels using the code label. The table below proposes a syntax that you can use as guideline:
Syntax for Different Types and Levels of Codes
| What | Syntax for Code Label | Example |
|---|---|---|
| Initial concept | Lower case | personal growth |
| Category | UPPER CASE, colored | EFFECT |
| Sub code | Lower case, same as category color | Effects pos: personal growth |
| Concept that does not fit any category | asterisk (*) label in lower case | *scientific evidence |
| Dimension | Lower case + special character, coloured | /time: during |
| Sociodemographics | prefixed with # | #gender: female |
| speaker units | prefixed with @ | @Tom |
Example
# gender: female
# gender: male
@Tom
@Maria
@Clara
/time: before
/time: during
/time: after
*single code 1
*single code 2
*single code 3
CATEGORY A
category A: sub 1
category A: sub 2
category A: sub 3
CATEGORY B
category B: sub 1
category B: sub 2
category B: sub 3
You see that the prefixes divide your code system into different sections. This helps you to keep organized and to quickly find what you are looking for. It also allows you to flexibly combine the codes of the different categories or categories with speakers, attributes and dimensions when querying the data.
To sort documents by attributes like gender, age, family status and the like if you have interview data, you use document groups.
tip
Organize your code structure based on conceptual similarities, not observed or theoretical associations, nor according to how you think your will want to write the result chapters.
Use a separate code for each element of what the text is about, i.e., each code should encompass one concept only. If there are multiple aspects, the passage can be coded with multiple codes.
Don't worry if not all of your codes can be sorted into a category. Some codes will remain single codes. In order not to "loose" them in the categories, use a special prefix, so they show up in their own section in the code system.
The Role of Code Groups in Building a Code System
Users are often tempted to use code groups as higher order categories. This defeats the purpose somehow. Code groups are filters and codes can be assigned to multiple code groups. A code of one category can however only belong to one and not to multiple categories. This is why code groups do not serve well as higher order codes. If you want to build categories and sub codes, the recommendation is using the above suggested syntax instead. Indicate a category by using capital letters.
Once you have developed categories with sub codes, you can create a code group for each category for the purpose of using it as filter (see image above). Code groups will allow you to filter by categories, and for further analysis, you can use the code groups to analyse on the category level rather than the sub code level. If you have a lot of low frequency code that you want or need to merge, then code groups are a good way to collect them. After you have added all low level codes that belong to the same theme / topic / idea, you can set this code group as filter. This makes it easier to merge the codes. You can then add prefixes, and the category code in capital letters.
Video Tutorial: Merging Codes
Moving on
Once the data is coded, you have a good overview of your material and can describe it. You can then take the analysis a step further by querying the data. The tools that can be used include the code co-occurrence table, the code document table, the query tool, and the net
The goal is to delve deeper into the data and find relationships and patterns. Writing memos is very important at this stage as much of the analysis does not just happen because you apply a tool. The insights come when reading the data resulting from a query, and when writing summaries and interpretations.
Literature
The recommendations in this section are based on the following authors:
Bazeley, Pat (2013). Qualitative Data Analysis: Practical Strategies. London: Sage. Friese, Susanne (2019). Qualitative Data Analysis with ATLAS.ti. London: Sage. Guest, Greg, Kathleen M. MacQueen, and Emily E. Namey (2012). Applied Thematic Analysis. Los Angeles: Sage. Richards, Lyn and Janice M. Morse (2013, 3ed). Readme first: for a user’s guide to Qualitative Methods. Los Angeles: Sage. Saldaña, Jonny (2015). The Coding Manual for Qualitative Researchers. London: Sage.
Retrieving Coded Data
Video Tutorial: Retrieving data - Quotation Reader
In the Code Manager
Open the Code Manager and double-click a code. This open the Quotation Reader. In the Quotation Reader you can review, edit and also delete codings.
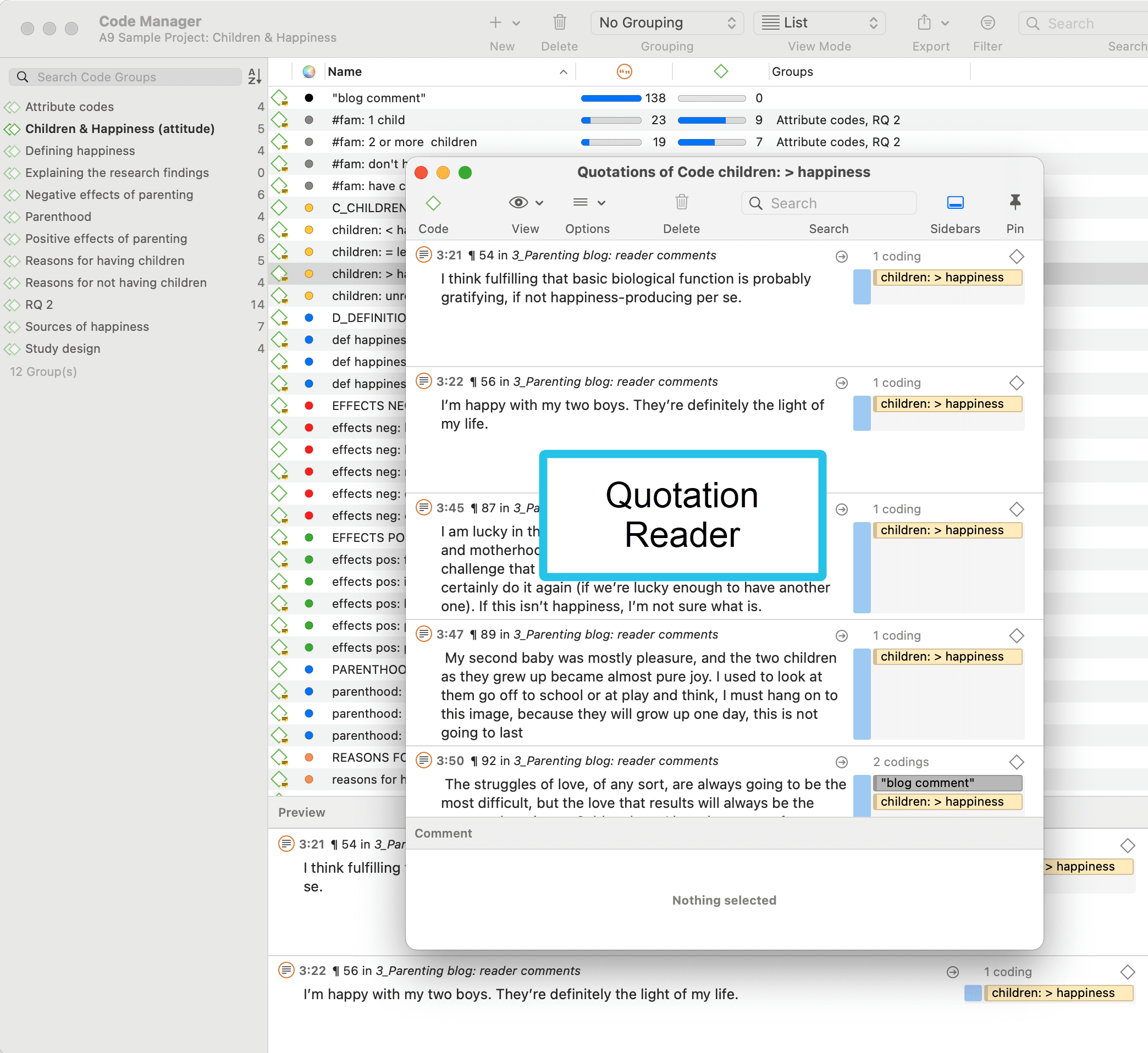
Simple Retrieval in the Margin Area
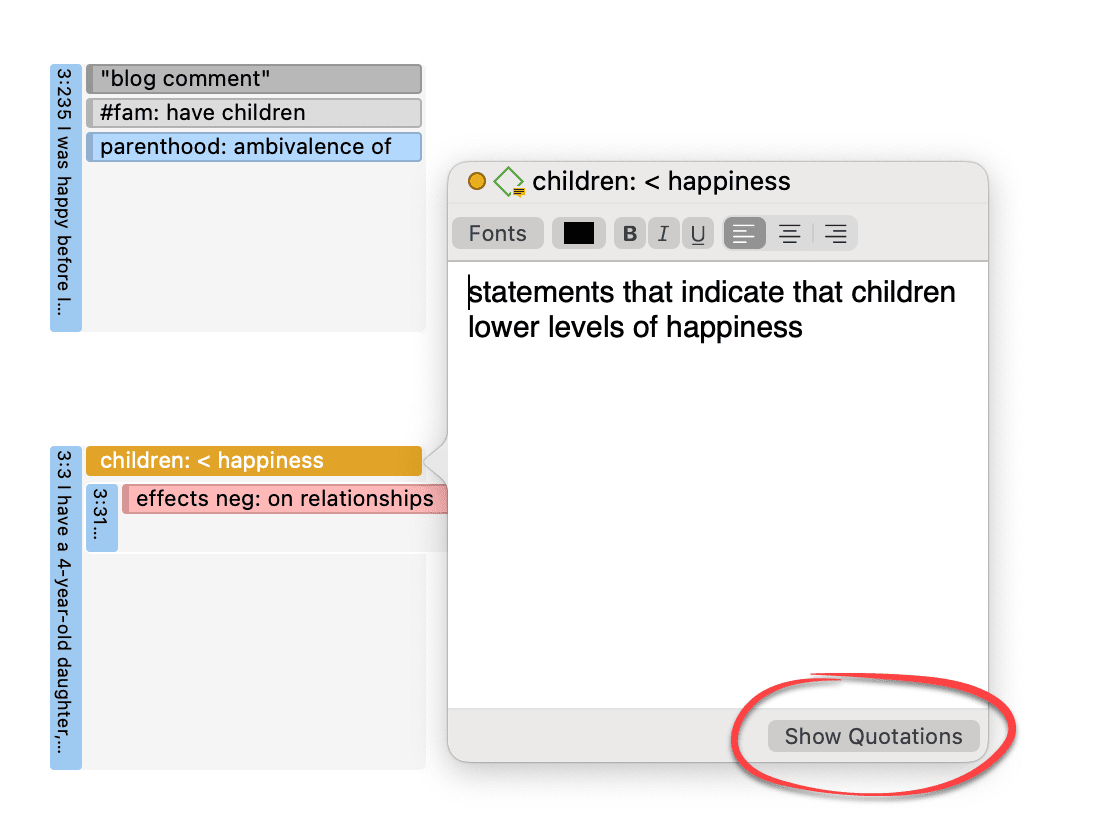
If you double-click on a code in the margin area, the comment field opens. From there you can access the quotations coded with the code.
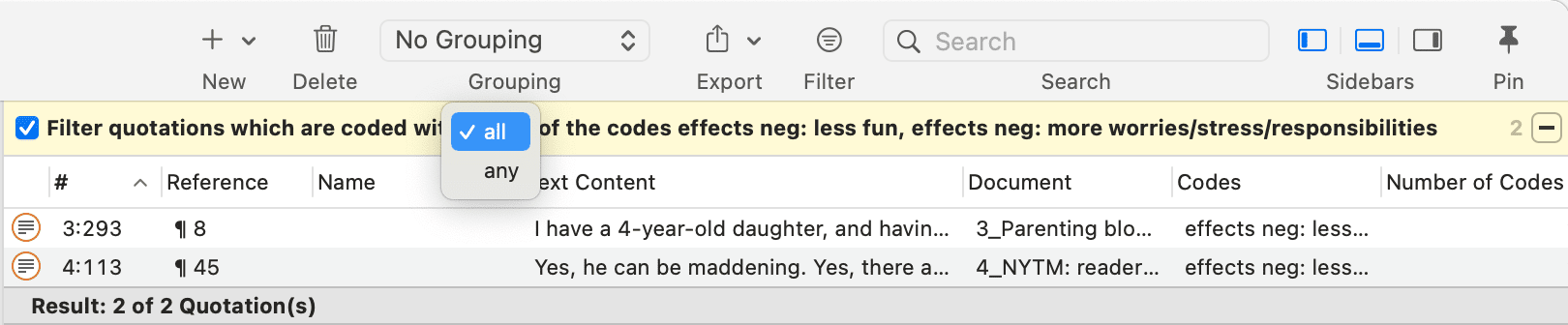
Simple AND and OR Queries in The Quotation Manager
Open the Quotation Manager.
Select a code in the filter area. The list of quotations only shows the quotations of the selected code. If you click on a quotation, it will be shown in the preview area. If you double-click, the quotation will be shown in the context of the document.
The yellow bar on top shows the code(s) you are using as filter.
When selecting two or more codes in the side panel, the filter is extended to an OR query - Filter quotations, which are coded with any of the codes.....
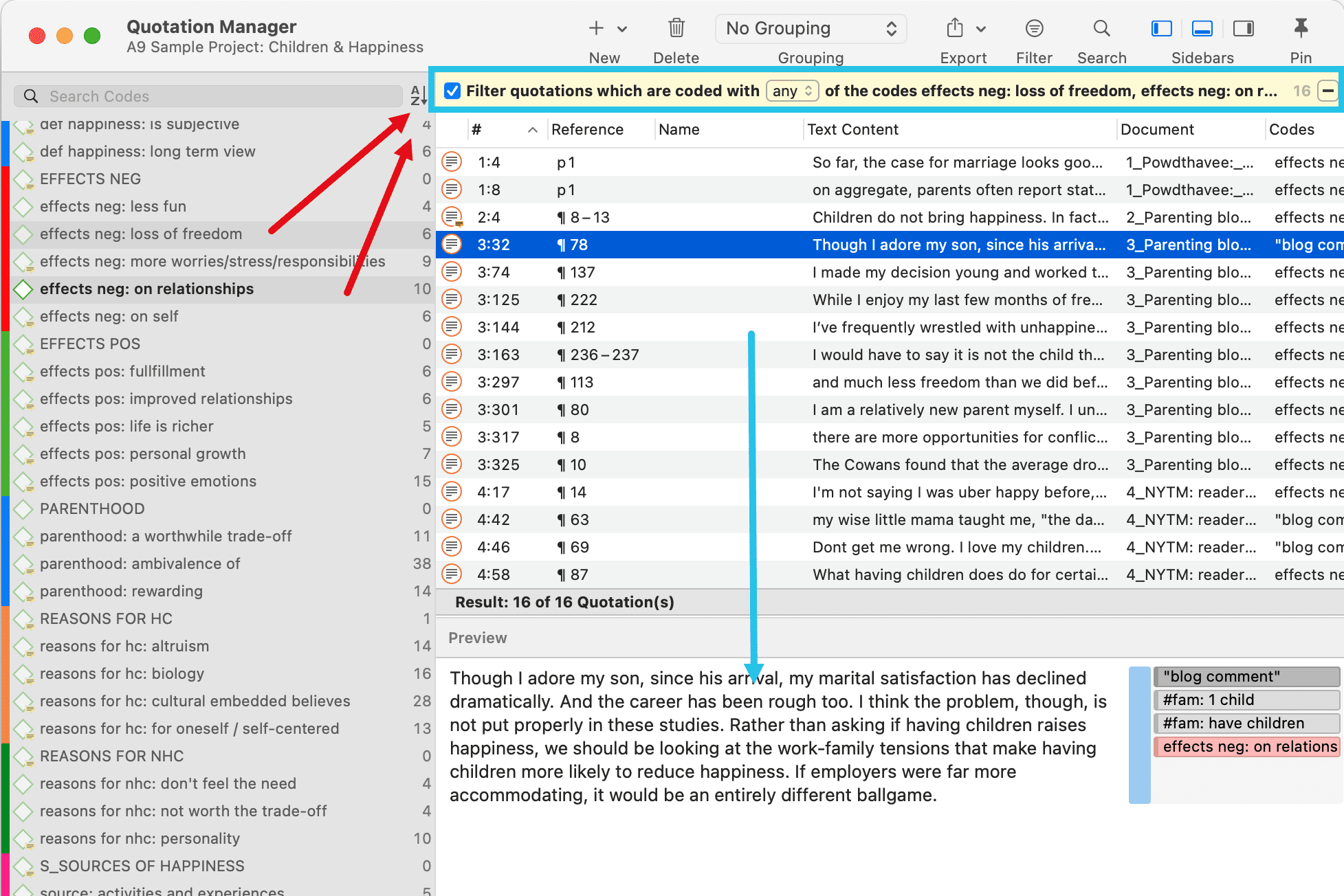
Click on the box with the any operator. This opens a drop-down, and you can change between ANY and ALL.
-
ANY: Show all quotations linked to any of the selected codes.
-
ALL Show quotations where all the selected codes apply. This means that two or more codes have been applied to the exact same quotation.
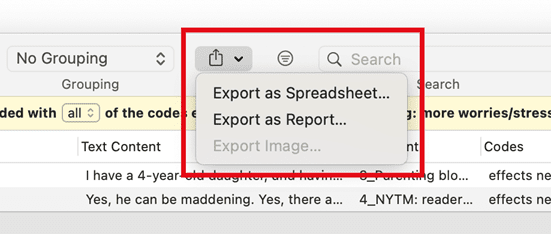
Exporting Results
If you want to export the results, click on Export button and select an option from the drop-down menu. For further information on available reports and report options, see Creating Reports.
Working with Memos and Comments
Memos
"Memos and diagrams are more than just repositories of thoughts. They are working and living documents. When an analyst sits down to write a memo or do a diagram, a certain degree of analysis occurs. The very act of writing memos and doing diagrams forces the analyst to think about the data. And it is in thinking that analysis occurs" (Corbin & Strauss: 118).
"Writing is thinking. It is natural to believe that you need to be clear in your mind what you are trying to express first before you can write it down. However, most of the time, the opposite is true. You may think you have a clear idea, but it is only when you write it down that you can be certain that you do (or sadly, sometimes, that you do not)" (Gibbs, 2005).
As you see from the above quotes, memos is an important task in every phase of the qualitative analysis process. Much of the analysis 'happens' when you write down your findings, not by clicking buttons in the software.
The ideas captured in memos are often the pieces of a puzzle that are later put together in the phase of report writing.
Theory-building, often associated with building networks, also involves writing memos.
Memos in ATLAS.ti can be just a text on its own, or can be linked to other entities like quotations, codes, or other memos.
Typical Usage of Memos
-
Memos can contain a project description
-
You can list all research questions in a memo.
-
You can use memos to write a research diary.
-
You can use one memo as to do list.
-
Memos can be used as a bulletin board to exchange information between team members.
-
You can store definitions, findings or theories from relevant literature in one or more memos.
-
You can write up your analysis using memos. Those memos will be the building blocks for your research report.
Memos can also be assigned as documents, if you want to code them. See Using Memos as Document .
Differences between Memos and Comments
From a methodological point of view comments are also memos in the sense that comments are also places for thinking and writing.
In technical terms, in ATLAS.ti there is a distinction between comments and memos, as comments exclusively belong to one entity. For example, the document comment is part of the document; a code comment belongs to a particular code and is usually a definition for this code. A quotation comment contains notes or interpretations about the quotation it belongs to.
Comments are not displayed in browsers separately from the entity to which they are attached.
ATLAS.ti memos in comparison
- can be free-standing, or they can be linked to other entities.
- You can write a comment for a memo, for example: use this memo for section 2 in chapter 4 in my thesis.
Typical Usage of Comments
Below some ideas are listed for what you can use comments:
Project comment
- project description
Document comment
- Meta information about a document: source, where and how you found or generated it
- Interview protocols
Information about a respondent like gender, age, profession etc., are best handled by document groups. There is no need to write this type of information into the comment field.
Quotation Comment
- interpretations that only concern a specific data segment
- ideas how a quotation might be related to another quotation
- summaries for what you hear or see in the multimedia quotation
- interpretations of image quotations
- notes on a geo position

Code Comment
- first ideas what you mean by a code
- a code definition
- a coding rule, especially when working in a team
- an example of what kind of data can be coded with this code
- summary of coded segments
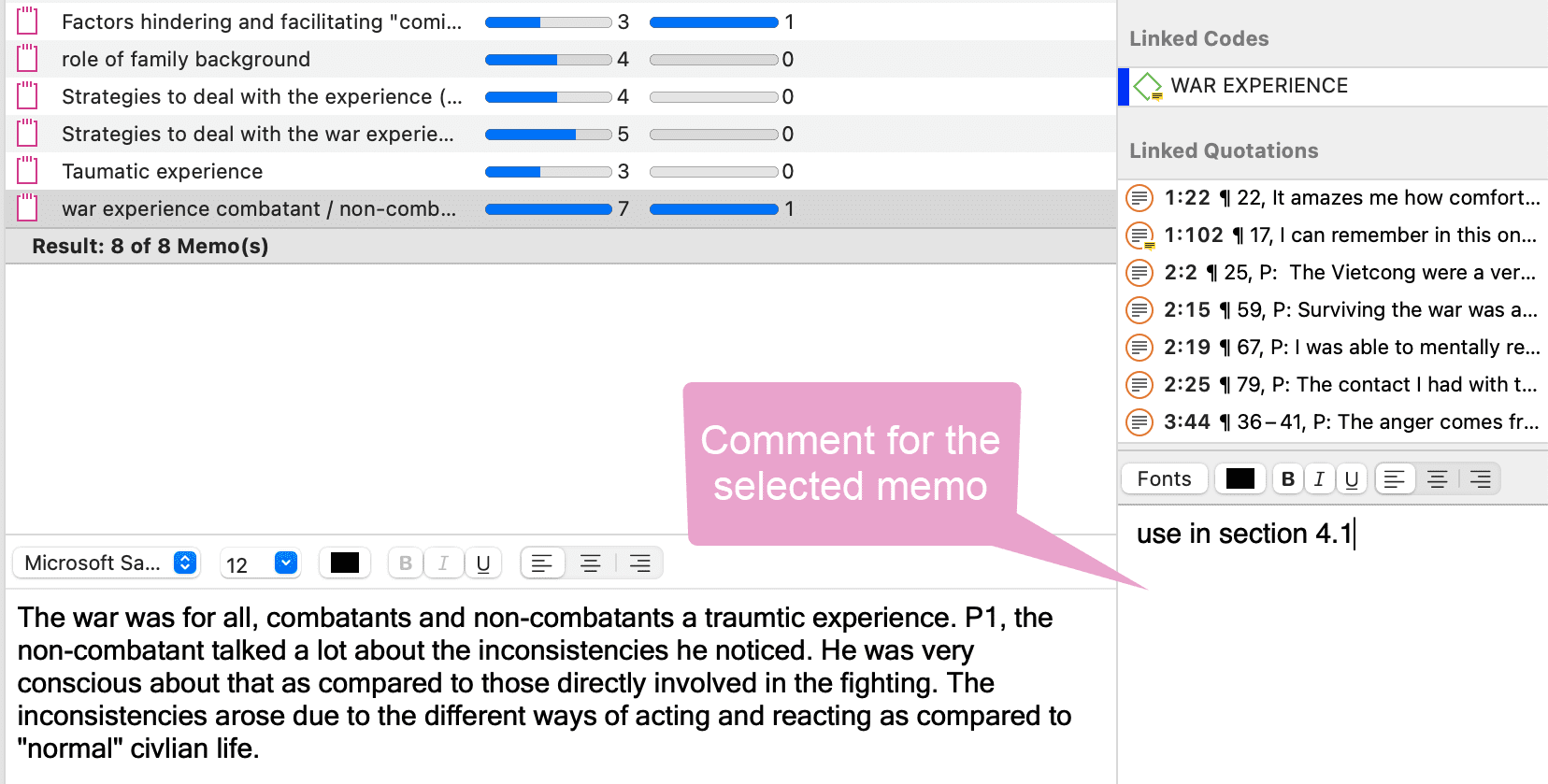
Memo Comment
- note to yourself where you want to use the memo in a report
- comments from supervisors or team members
- links to or notes about relevant literature
Network Comment
- description of the network
- idea how you want to develop it further
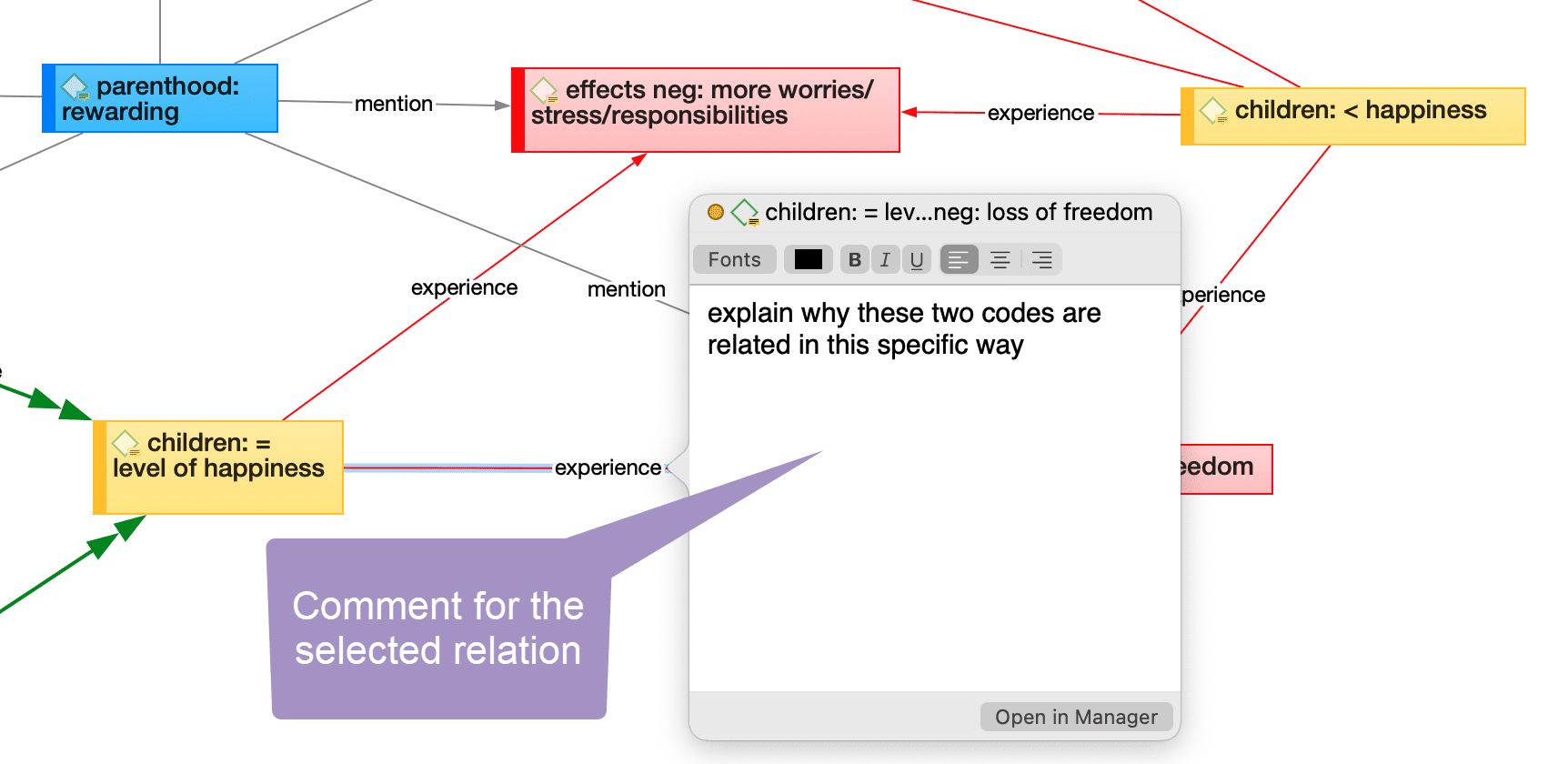
Link Comment
- Explaining why the two entities are linked in a specific way.
Writing a Comment
You find a field for writing comments in every Entity Manager.
To write a comment, select an item and type something in to the comment field in the inspector. Alternatively, you can right-click on any entity and select the Edit Comment option from the context menu. Both options are shown in the images. The comment is automatically saved.
All items that have a comment display a yellow post-it within their icon.
Creating Memos
Memos can be created from the toolbar, or in the Memo Manager.
To create a memo from the toolbar:
Click the drop-down menu for Memos and select New Memo. A new memo opens immediately, and you can change the default name in the inspector.
To create a memo in the Memo Manager
From the main menu select Memo > Show Memo Manager.
In the Memo Manager, click on the plus. A new memo is created in the list, and you can enter a title. You can begin to write your memo in the editor in the lower part of the Memo Manager.
Adding a Quotation to a Memo
You can copy and past quotations into a memo. This is for example useful if you want to include key quotes in your report.
Select a quotation, right-click and select Copy from the context menu, ir the short-cut cmd+c.
Paste the quotation in the memo editor, either using the short-cut cmd+v, or the context menu option. The quotation will be pasted into the memo including its reference, i.e., document name and location within in the document.

You can also copy and paste a quotation including its reference into any text editor, also outside of ATLAS.ti.
Opening an Existing Memo
You can access memos from everywhere: the Project Explorer, the Memo Manager, in the margin area if you linked a memo to a quotation, or from within a network.
If you want to review or continue to work on a memo, just double-click the memo. In the Memo Manager, you can select a memo with a single click and review and edit it in the lower part of the manager window.
Memos can be linked to quotations, codes and other memos. You can link memos per drag & drop basically anywhere in the program, or visually in networks. See Linking Nodes. Below a few examples are given.
References
Corbin, Juliet and Strauss, Anselm (2008). Basics of Qualitative Research: Techniques and Procedures for Developing Grounded Theory (3rd and 4th ed.). Thousand Oaks, CA: Sage.
Gibbs, Graham (2005). Writing as analysis. Online QDA.
Querying Data
ATLAS.ti offers several tools that support you in querying your data:
Simple Boolean Retrieval.
Code Document Table
The Code Document Table is a cross-tabulation of codes or code groups by documents or document groups. It shows how often a code (codes of a code group) has (have) been applied to a document or document group. See Code Document Table.
Co-occurrence Analysis
Use the Code Co-occurrence Explorer to explore coded data to get a quick overview where there might be interesting overlaps. If you are looking for specific co-occurrences and for accessing the quotations of co-occurring codes, the Code Co-occurrence Table is the better choice. See Code Co-Occurrence Table.
The Query Tool
The Query Tool finds quotations based on a combination of codes using Boolean, Proximity or Semantic operators. Example: Show me all quotations where both Code A and Code B have been applied.
Such queries can also be combined with variables in form of documents or document groups. This means that you can restrict a query to parts of your data like: Show me all quotations where both Code A and Code B have been applied, but only for female respondents between the age of 21 and 30. See the chapters on the Query Tool in the full manual.
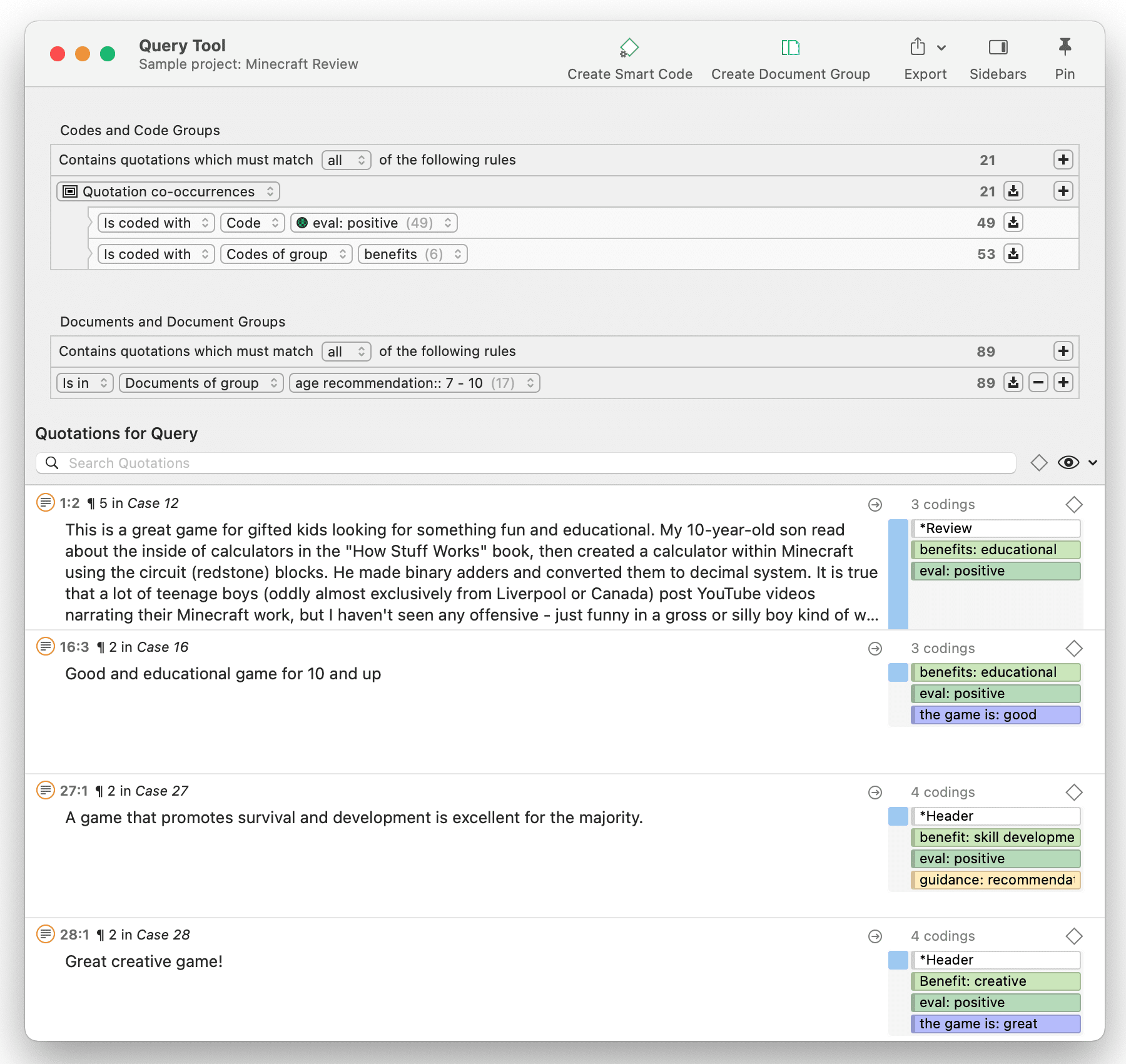
Smart Codes
Smart Codes are stored queries. They can be reused and always reflect the current state of coding, e.g. after more coding has been done or after coding has been modified. They can also be used as part of other query, thus, you can build complex queries step by step. See the chapter "Working With Smart Codes" in the full manual.
Smart Groups
Like smart codes, smart groups are stored queries based on groups. The purpose is to create groups on an aggregate level. For instance, if you have groups for gender, age and location, you can create smart groups that reflect a combination of these like all females from age group 1 living in city X. See the chapter "Working With Smart Groups" in the full manual.
Global Filters
Global filters allow you to restrict searches across the entire project. If you set a document group as global filter, the results in the Codes-Document or Code Co-occurrence Table will be calculated based on the data in the filter and not for the entire project. Global filters effect all tools, windows, and networks. See the chapter "Applying Global Filters For Data Analysis" on the full manual.
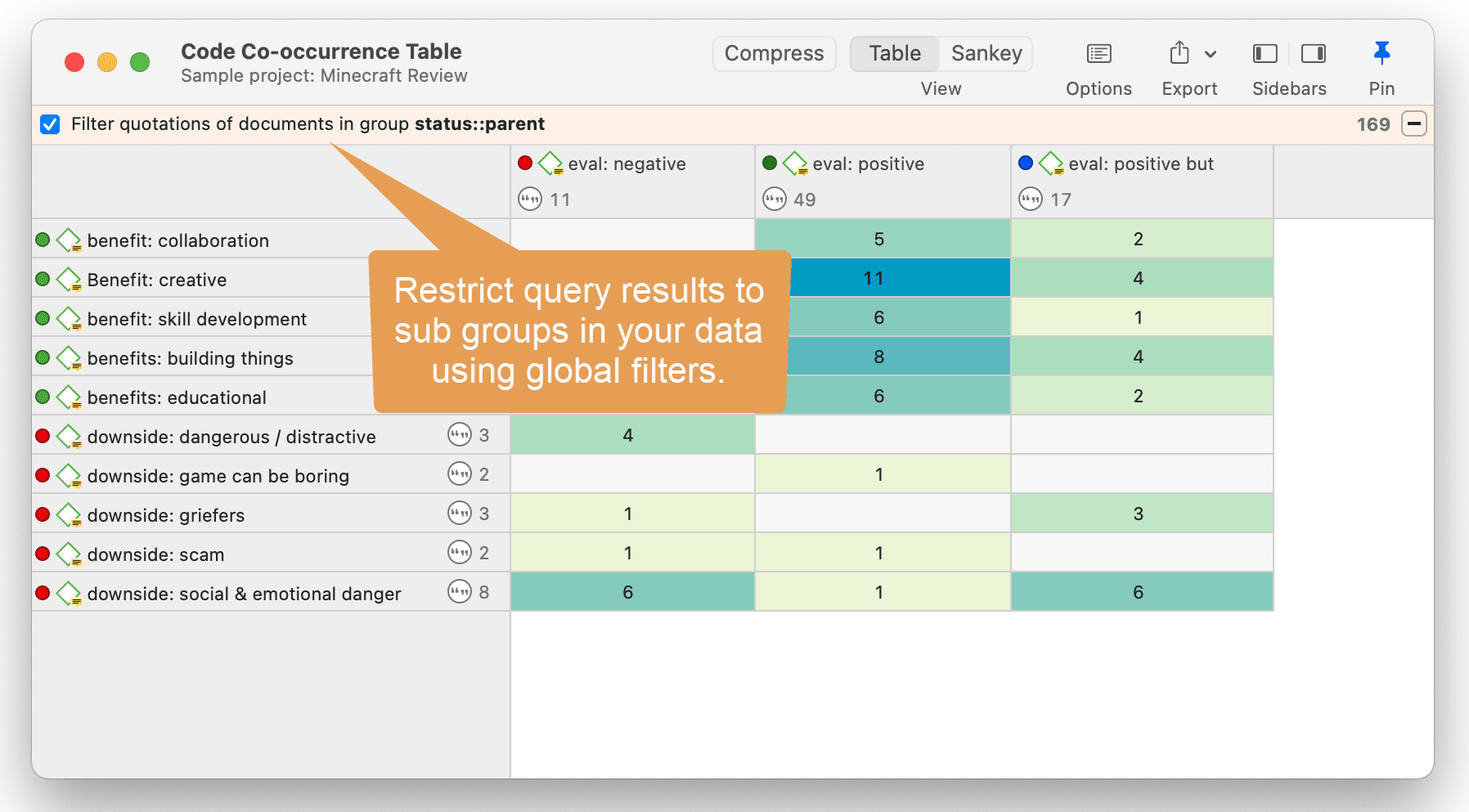
Code-Document Table
Video Tutorial: Working with the Code-Document Table
You can use the Code Document Table for within and across documents or group comparisons by relating codes or code groups and documents or document groups to each other. The table cells contain:
-
frequency count of the number of codings. This can be different from the number of quotations, if a quotation is coded by multiple codes. Counted is each link between a code and a quotation.
-
word count of the quotations coded by the selected code or code group.
Running an Analysis in the Code Document Table
From the main menu select Analysis > Code-Document Table.
Select codes or code groups for the table rows; and select documents or document groups for the table columns.
tip
How to make selections: To select an item, you need to click the check-box in front of it. It is also possible to select multiple items via the standard selection techniques using the cmd or shift-key. After highlighting multiple items, push the space bar to activate the check boxes of all selected items.
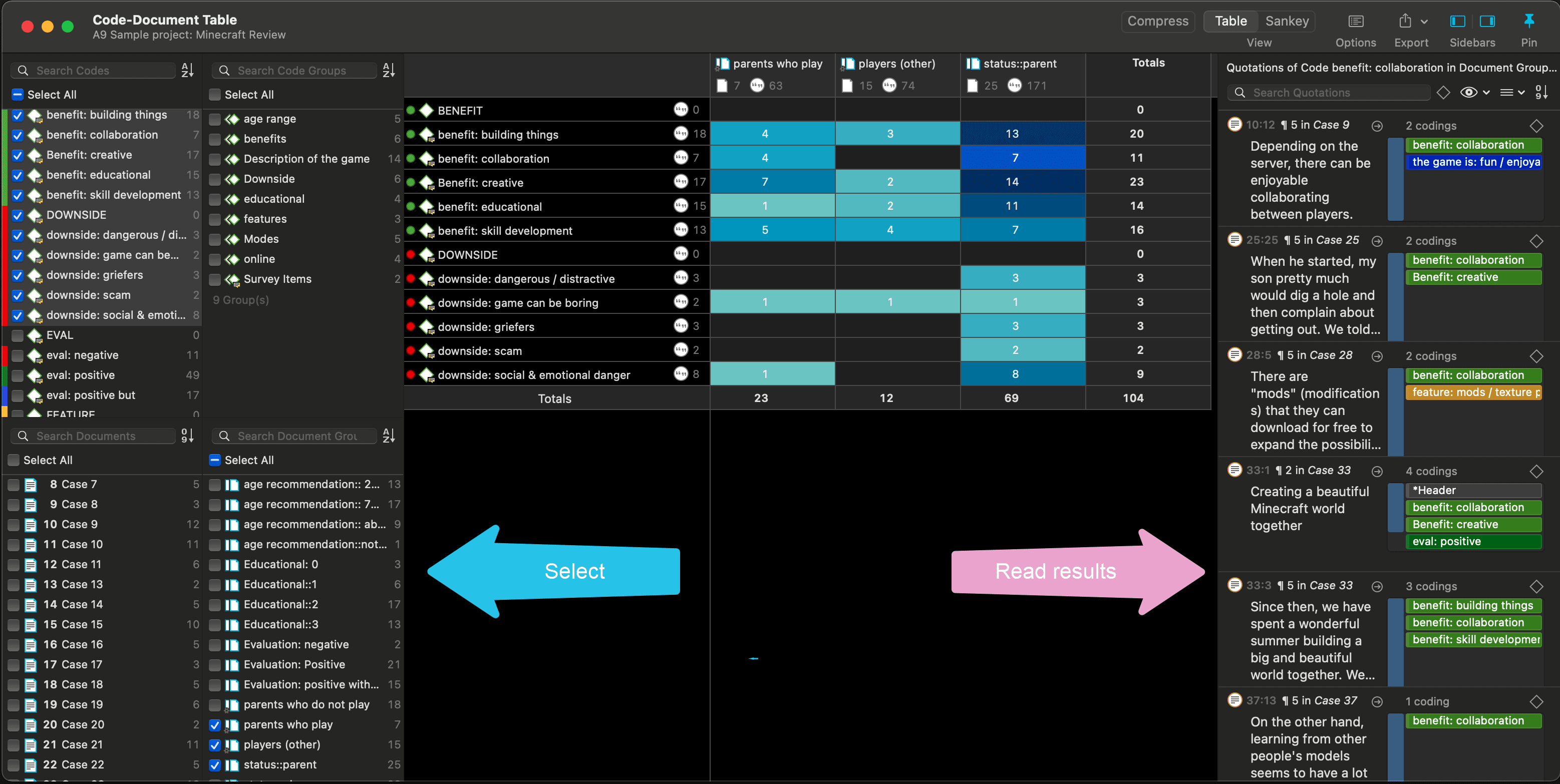
Code-Document Table in dark mode
How to read
By default, the codes / code groups are displayed in the left column, and the documents / document groups in the top row. Left column
-
Next to each code, the number indicates how often the code is applied in the entire project.
-
Next to a code group, you see two numbers: The first one tells you how many codes are in the group, the second numbers gives you the number of codings. This is different from the number of quotations, as multiple codes from the same code group could be linked to the same quotation.

Top row
-
Below a document, you see the total number of quotations in each document.
-
Below a document group, you see two numbers: the first one tells you how many documents are in the document group, and the second number gives you the number of quotations for all documents in the group.
The additional information you get for each selected row or column item allows you to better evaluate the numbers inside the table cells. If the value in the table cell is 10, but the code overall was applied 100 times, this leads to a different interpretation as if the code was only applied 12 times in the entire project.
Table cells
-
The results in the table cells show how often each selected code was (or the codes of a code group were) applied in each document or document group. Counted are the number of codings, unless you select to count words (see options).
-
If you click on a cell in the table, the quotation content is shown in the Quotation Reader on the left-hand side.
-
the table cells are colored to reflect the frequency. The darker the color, the higher the frequency.
Code-Document Table Toolbar

Compress: This is a quick way to remove all rows or columns that only show empty cells. This is the same as manually deactivating codes or documents that yield no results. Thus, you cannot decompress a table.
Table / Sankey: You can switch between table view, and a visualization of the selected data in form of a Sankey diagram. Fur further information see below and the full manual.
Options: See the full manual.
Export: You can export the table as Excel spreadsheet, and the Sankey diagram as image in pgn format.
Sankey Diagram
As soon as you create a table, a Sankey diagram will be shown in the area below the table. The Sankey diagram ist an alternative view complementing the original table view.
The basic table data model of rows and column entities is represented in the Sankey model as nodes and edges. The Code Document table uses codes, code groups, documents and document groups. For each table cell containing a value, an edge is displayed between the diagram nodes. The thickness of the edges resemble the cell values of the table. Cells with value 0 are not displayed in a Sankey view.
If you click on an edge, the corresponding quotations are displayed in a Quotation Reader on the left-hand side.
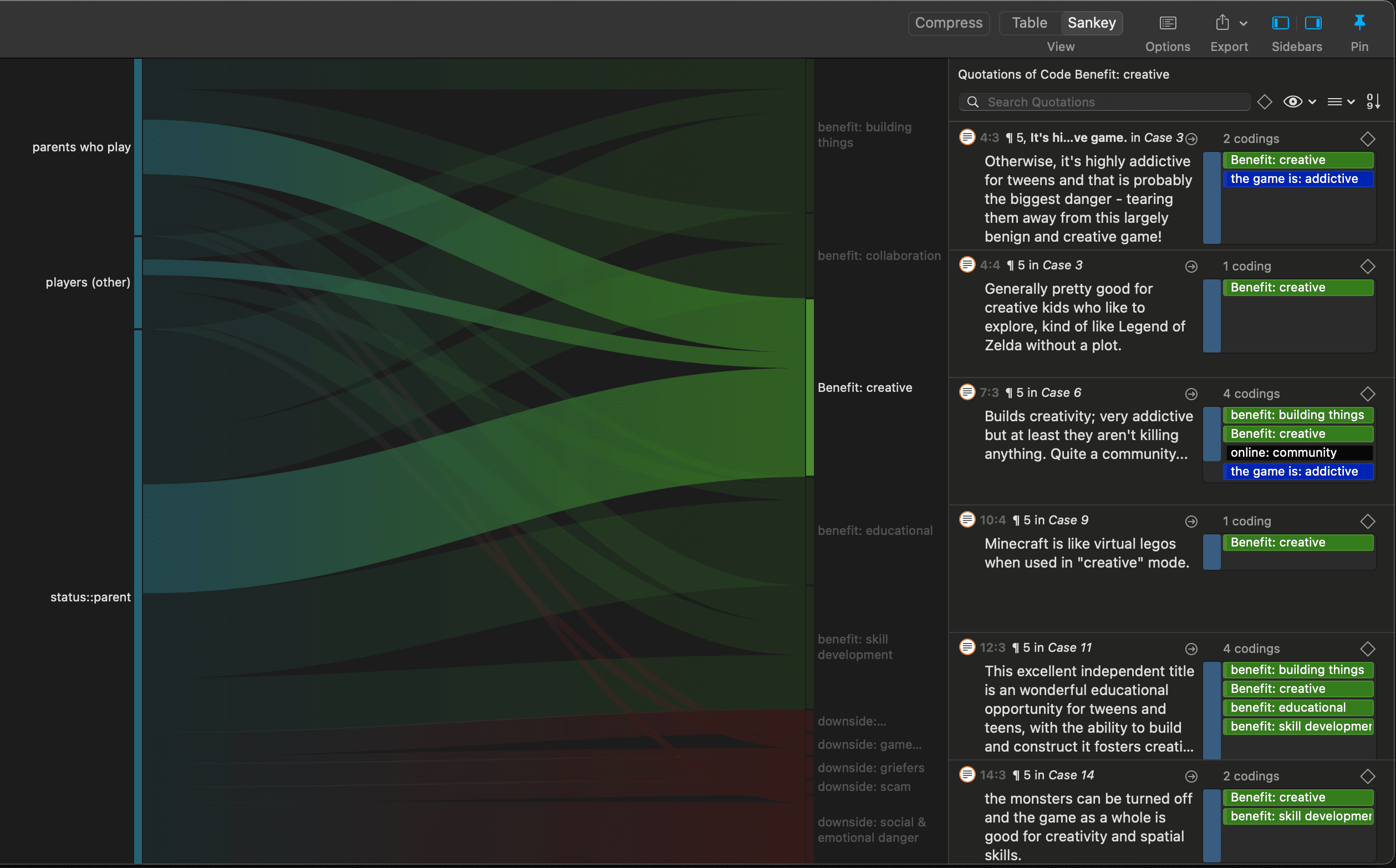
The Code Co-Occurrence Table
Video Tutorial: Code Co-occurrence Tools and Analysis
The Co-occurrence Table shows the frequencies of co-occurrence in form of a matrix similar to a correlation matrix that you may know from statistical software.
To open the tool, select Analysis > Code Co-occurrence Table.
Next you need to select the codes that you want to relate to each other:
Select codes from the first list for the table columns, and codes from the second list for the table rows. To select an item, you need to click the check-box in front of it. It is also possible to select multiple items via the standard selection techniques using the cmd or shift-key. After highlighting multiple items, push the space bar to activate the check boxes of all selected items.
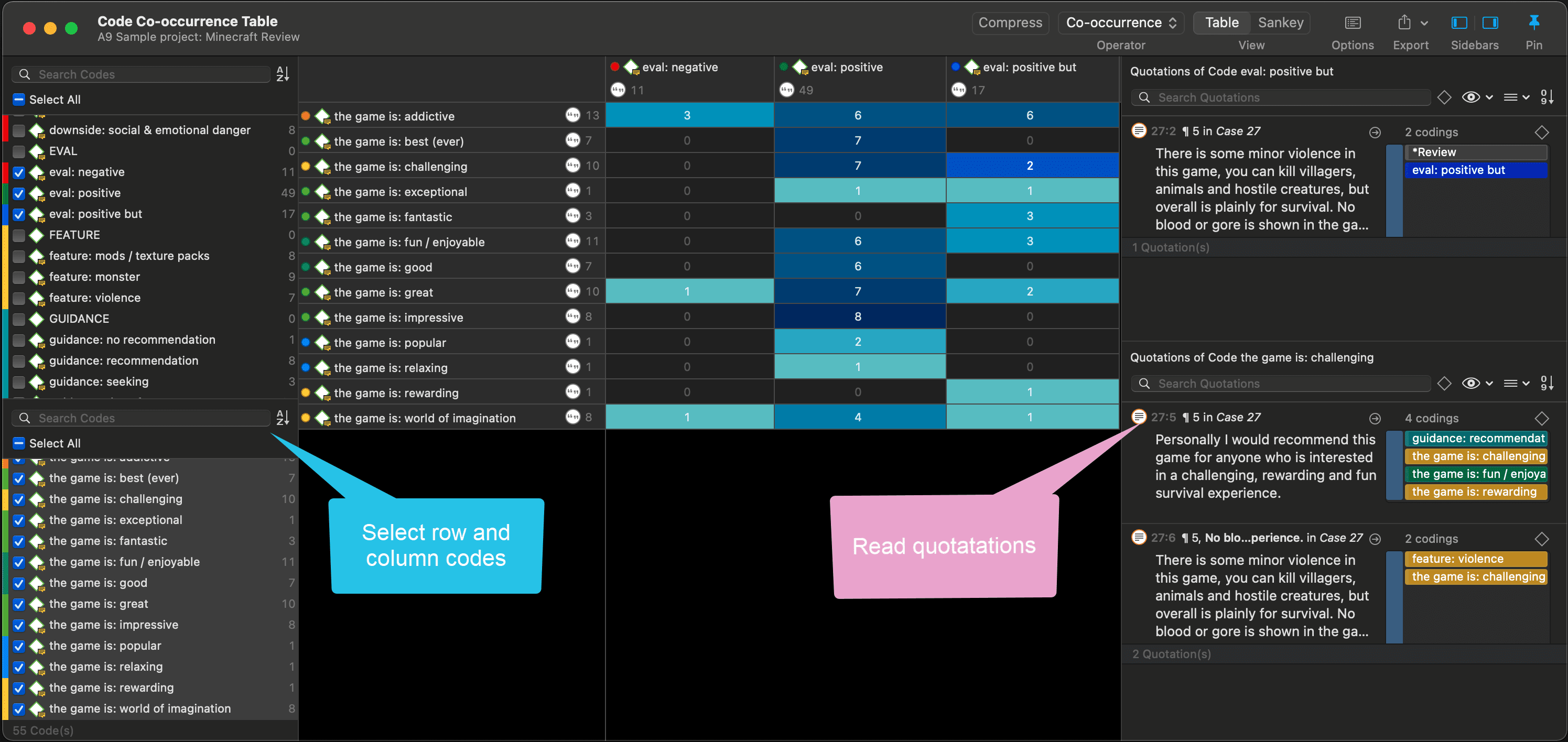
Code Co-occurrence Table in dark mode
How to read the table
First column / first row: The number below and behind each code shows how often the code is applied in the entire project. This helps you to better evaluate the number of co-occurrences in the table cells.
The number in the cell indicates the number of hits, how often the two code co-occur. This means that the number of co-occurring „events" and not the number of quotations are counted. If a single quotation is coded by two codes or if two overlapping quotations are coded by two codes, this counts in both cases as a single co-occurrence.
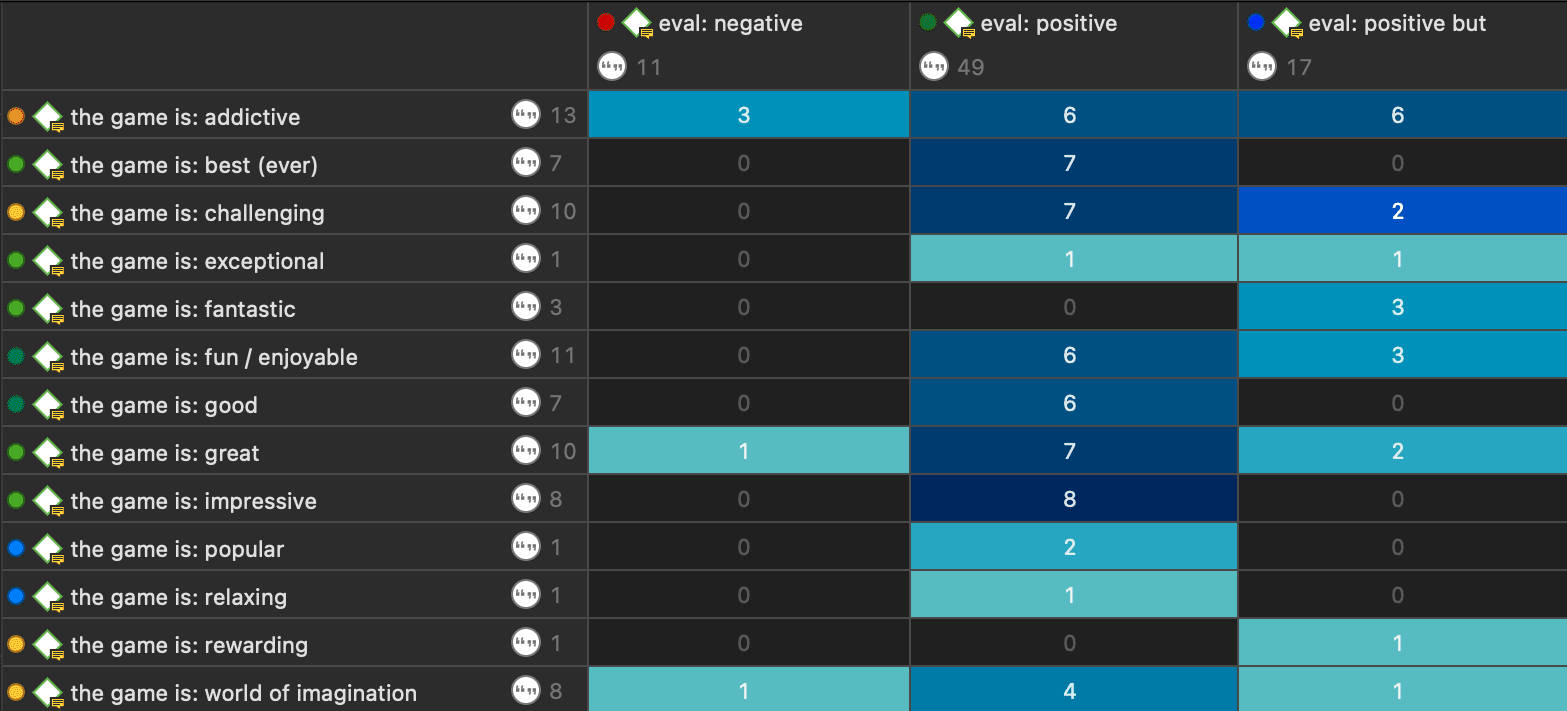
Retrieving the qualitative data: If you click on a cell, the quotations of the corresponding row and column codes are displayed next to the table in the Quotation Reader.
The quotation reader always displays two lists of quotations: the quotations of the column code, and the quotations of the row code.
Code Co-Occurrence Table Toolbar

Compress: This is a quick way to remove all rows or columns that only show empty cells. This is the same as manually deactivating codes that yield no results. Thus, you cannot decompress a table!
Operator: You can switch between the Co-occur and the AND operator. If the table cells should only show a result if the quotations overlap 100%, thus the two codes code exactly the same data segment, then you can select AND :
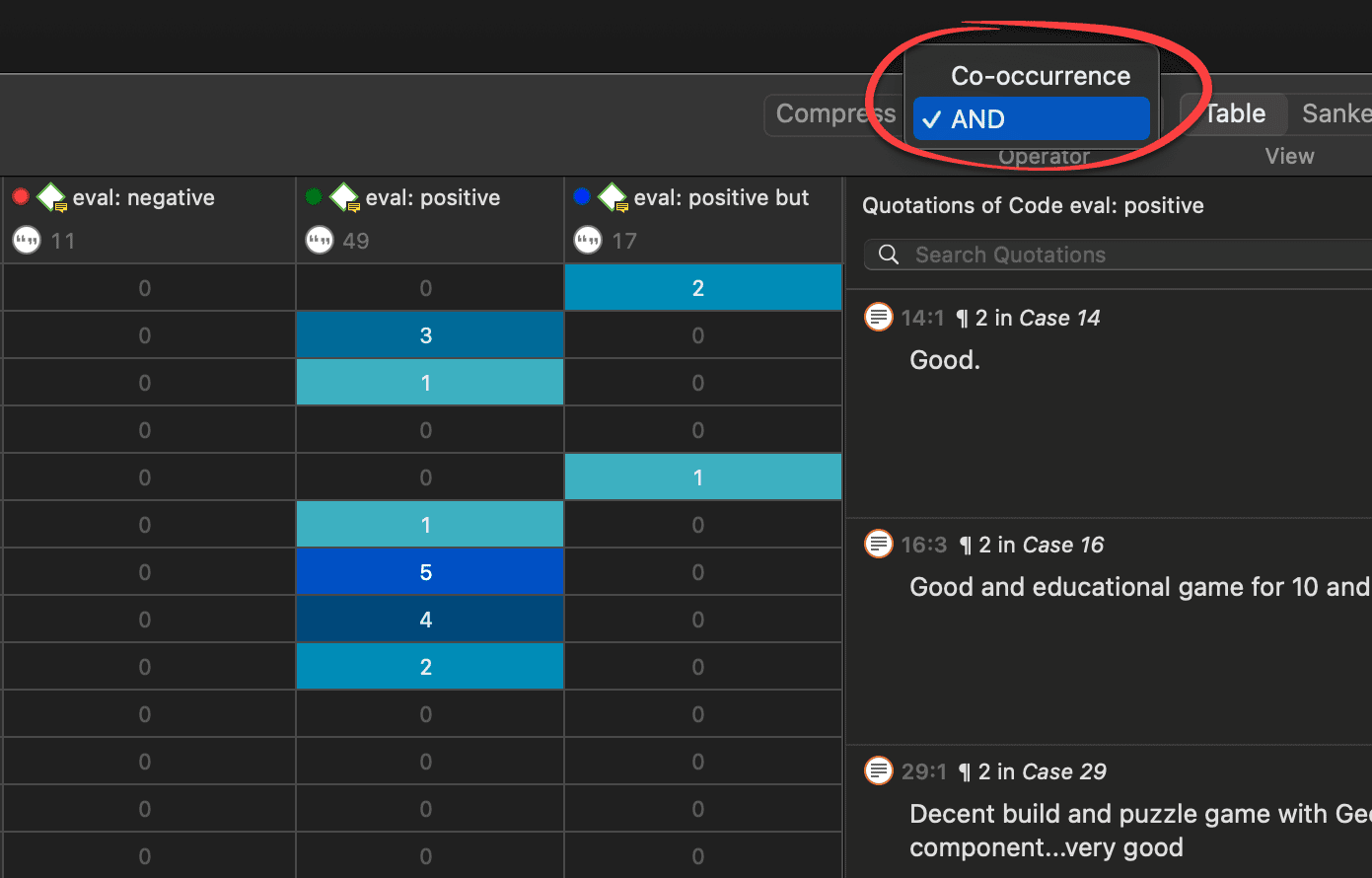
The table now only displays quotations that are coded by both the row and column codes
Table / Sankey: You can switch between table view, and a visualization of the selected data in form of a Sankey diagram. For further information, see below and the full manual.
Options: For further information, see the main manual.
Export: You can export the table as Excel spreadsheet, and the Sankey diagram as image.
Sankey Diagram
As soon as you create a table, a Sankey diagram will be shown in the area below the table. The Sankey diagram ist an alternative view complementing the original table view.
The basic table data model of rows and column entities is represented in the Sankey model as nodes and edges, the strength of co-occurrence between pairs of nodes. For each table cell containing a value, an edge is displayed between the diagram nodes. The thickness of the edges resemble the cell values of the table. Cells with value 0 are not displayed in a Sankey view.
If you select an edge, the corresponding quotations are displayed on the right-hand side in a Quotation Reader.
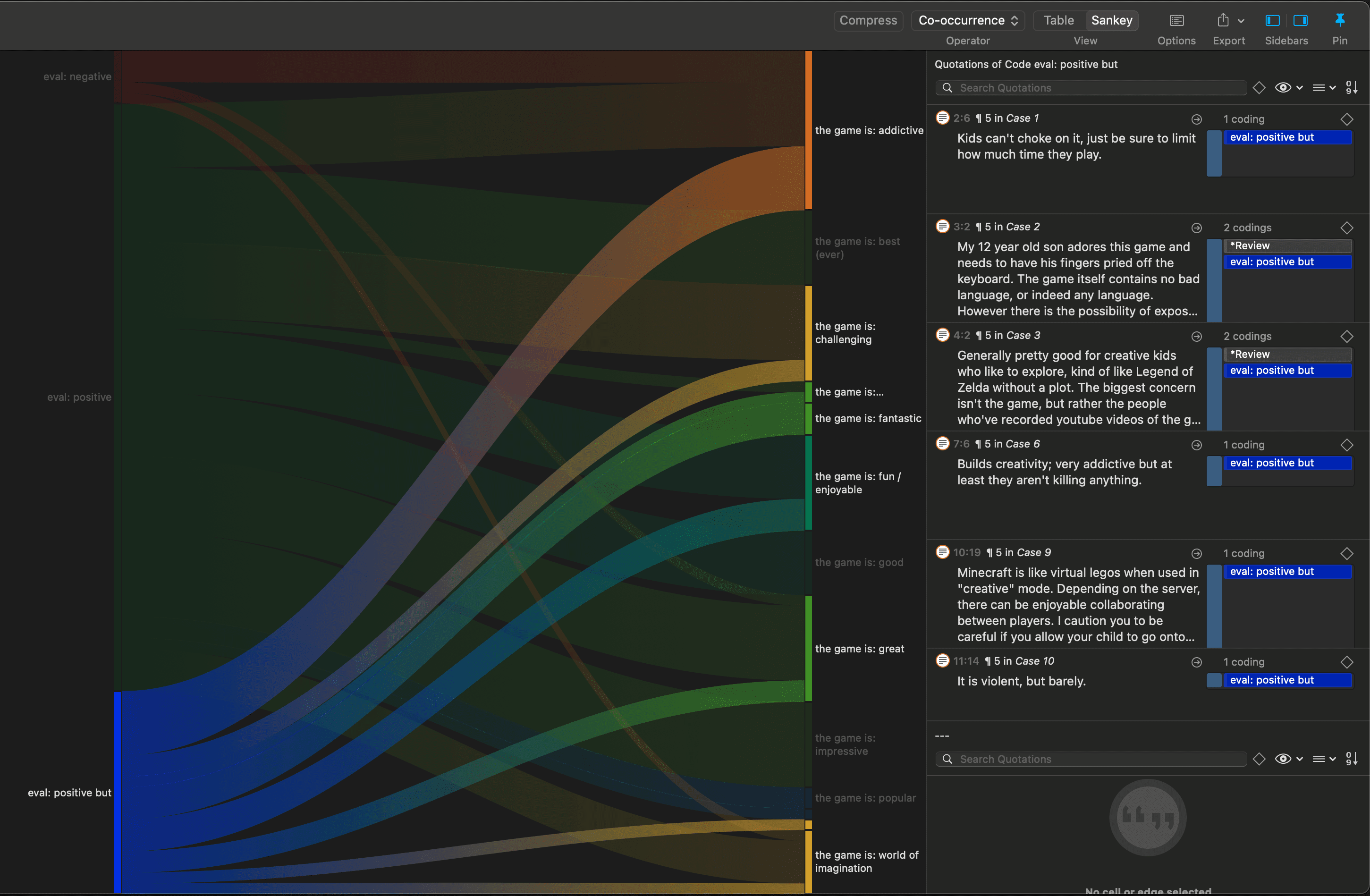
Sankey diagram with one edge highlighted
ATLAS.ti Networks
Video Tutorial: Visualizations in Building the Understanding
Visualization can be a key element in discovering connections between concepts, interpreting your findings, and effectively communicating your results. Networks in ATLAS.ti allow you to accomplish all three of these important objectives. These small segments of your larger web of analysis are modeled using the network editor, an intuitive work space we also like to think is easy on the eye.
The word network is a ubiquitous and powerful metaphor found in many fields of research and application. Flow charts in project planning, text graphs in hypertext systems, cognitive models of memory and knowledge representation (semantic networks) are all networks that serve to represent complex information by intuitively accessible graphic means. One of the most attractive properties of graphs is their intuitive graphical presentation, mostly in form of two-dimensional layouts of labeled nodes and links.
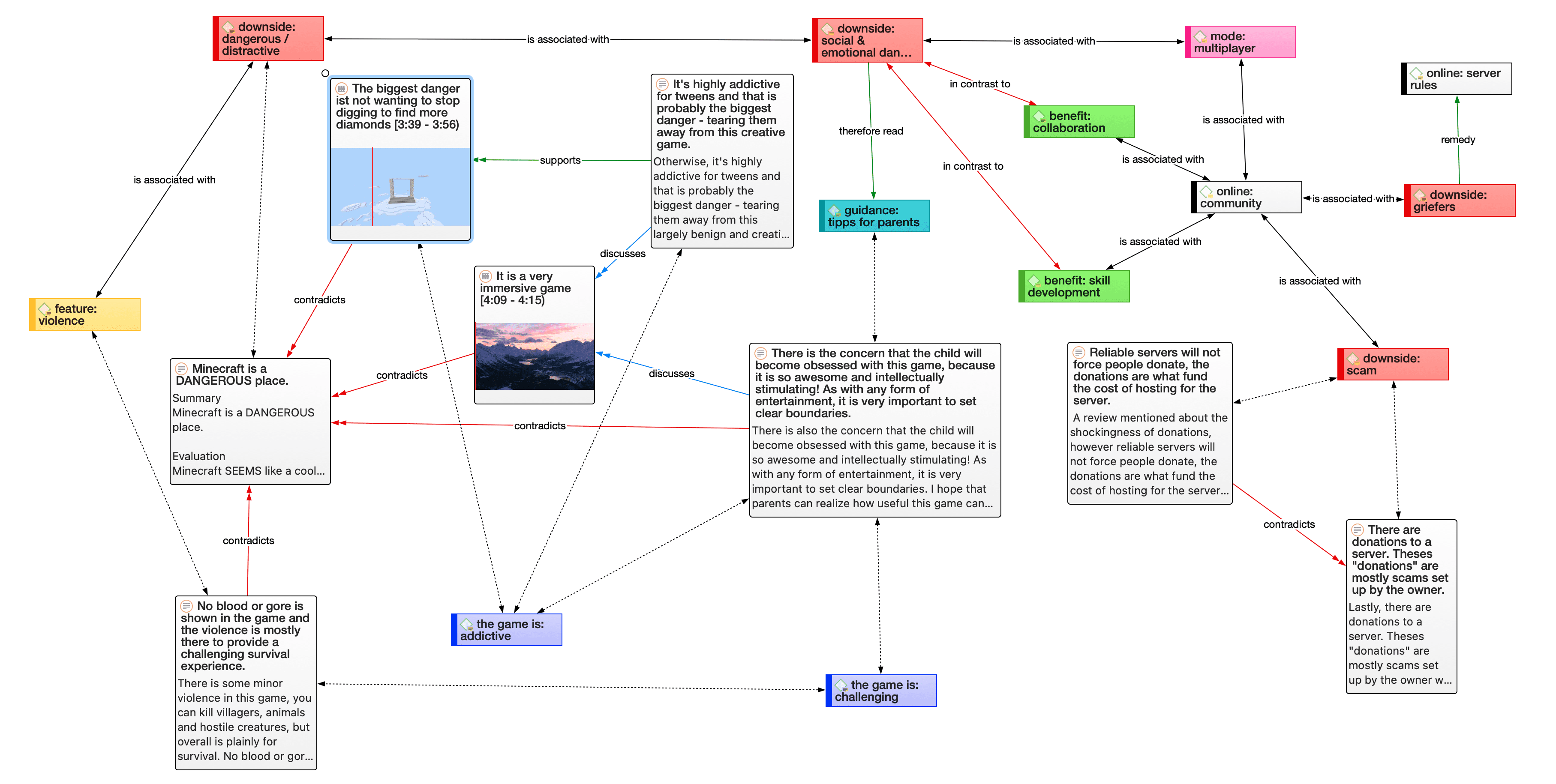 In contrast with linear, sequential representations (e.g., text), presentations of knowledge in networks resemble more closely the way human memory and thought is structured. Cognitive "load" in handling complex relationships is reduced with the aid of spatial representation techniques. ATLAS.ti uses networks to help represent and explore conceptual structures. Networks add a heuristic "right brain" approach to qualitative analysis.
In contrast with linear, sequential representations (e.g., text), presentations of knowledge in networks resemble more closely the way human memory and thought is structured. Cognitive "load" in handling complex relationships is reduced with the aid of spatial representation techniques. ATLAS.ti uses networks to help represent and explore conceptual structures. Networks add a heuristic "right brain" approach to qualitative analysis.
The user can manipulate and display almost all entities of a project as nodes in a network: quotations, codes, code group, memos, memo groups, other networks, documents, document groups and all smart entities.
If you are interested in learning more about network theory and how it is applied in ATLAS.ti, you can watch the following video: Did you ever wonder what's behind the ATLAS.ti network function.
Basic Network Procedures
Two methods for creating networks are available. The first one creates an empty network, and you begin to add entities as sequential steps. The other method creates a network from a selected entity and its neighbors.
Creating a New Network
Open the drop-down menu for Networks in the toolbar, and select New Network. The network opens immediately in the main space. It is recommend to change the default name in the inspector.
Another option is to open the Network Manager and to create a new network there by clicking on the plus button.
Adding Nodes to a Network
You can add nodes via the Add Nodes button in the toolbar, or via drag-and-drop.
Adding Nodes Using the Selection List
Click on the Add Nodes button in the toolbar.

This opens a selection list that is docked to the left-hand side of the network. At the bottom of the selection list you see a preview if one is available for the selected entity.
inst
Select the entity type and then the entities that you want to add to the network. Double-click to add the entity to a network; or drag-and-drop the selected entities to the network; or click on the Add button.
Adding Nodes via Drag &
You can add nodes by dragging entities into the network editor from entity managers, group managers, the margin, the project explorer, or any of the browsers.
Open a network and position it for example next to the Project Explorer.
Select the node(s) you want to import into the network and drag-and-drop them into the editor.
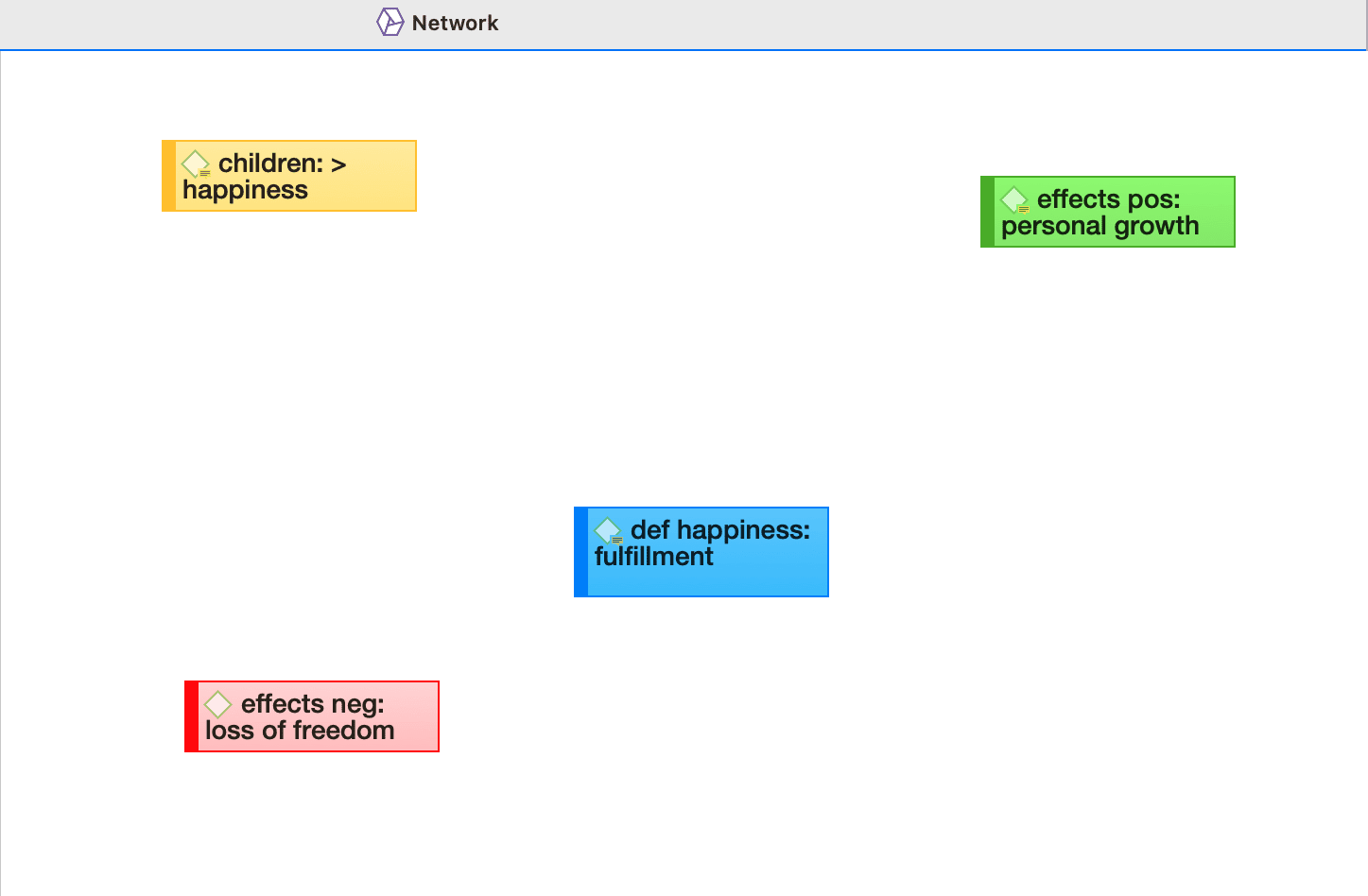
Selecting Nodes
Selecting nodes is an important first step for all subsequent operations targeted at individual entities within a network.
Selecting a Single Node
Move the mouse pointer over the node and left-click.
All previously selected nodes are deselected.

Selecting Multiple Nodes
Method 1
Hold down the cmd key on your keyboard, move the mouse pointer over the node and left click. Repeat this for every node you want to select.
Method 2
This method is very efficient if the nodes you want to select fit into an imaginary rectangle.
Move the mouse pointer above and left to one of the nodes to be selected. Hold down the left mouse button and drag the mouse pointer down and right to cover all nodes to be selected with the selection marquee. Release the mouse button.
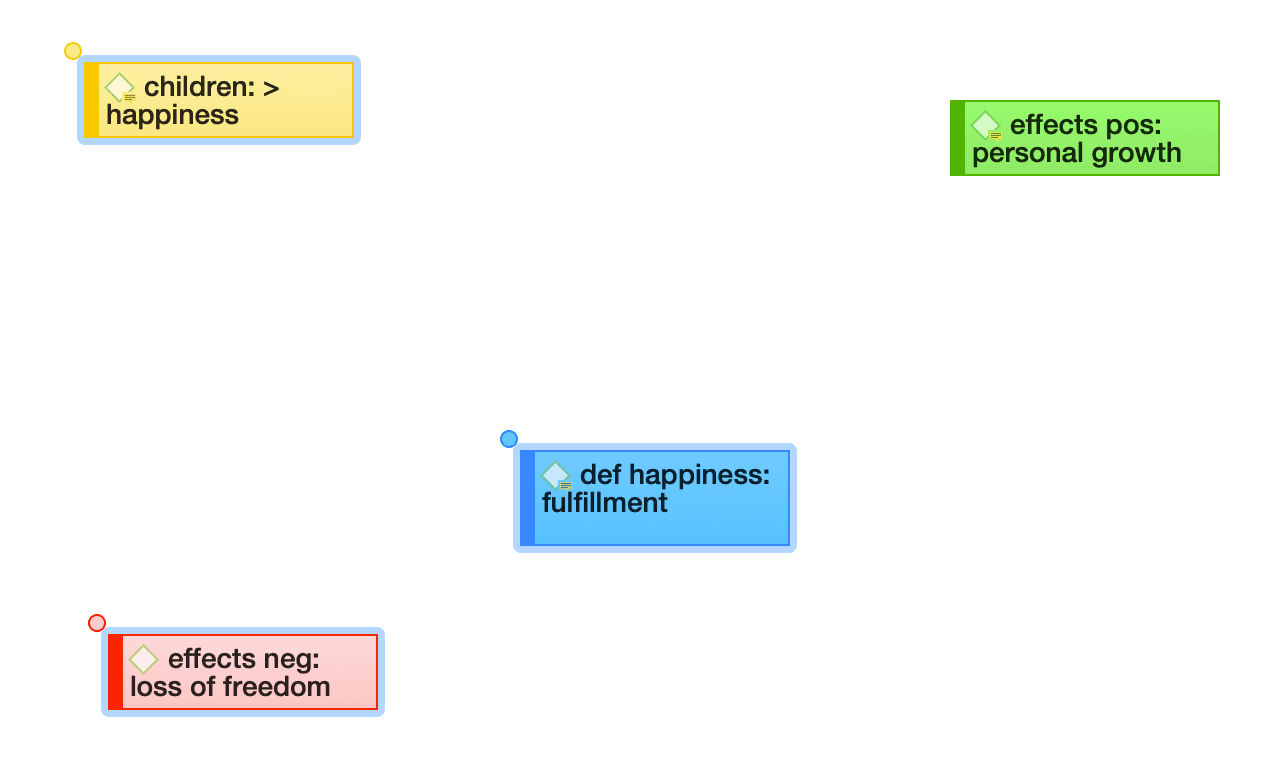
Linking Nodes and Entities
Select one or more nodes. A dot appears in the top left corner of the node(s). Click on the dot with the left mouse button and drag the mouse pointer to the node that you want to link. In case you have highlighted more than one node, you need to select the dot of one of the nodes.
Release the left mouse button on top of the node. If you link codes to codes or quotations to quotations, a list of relation opens. Select a relation.
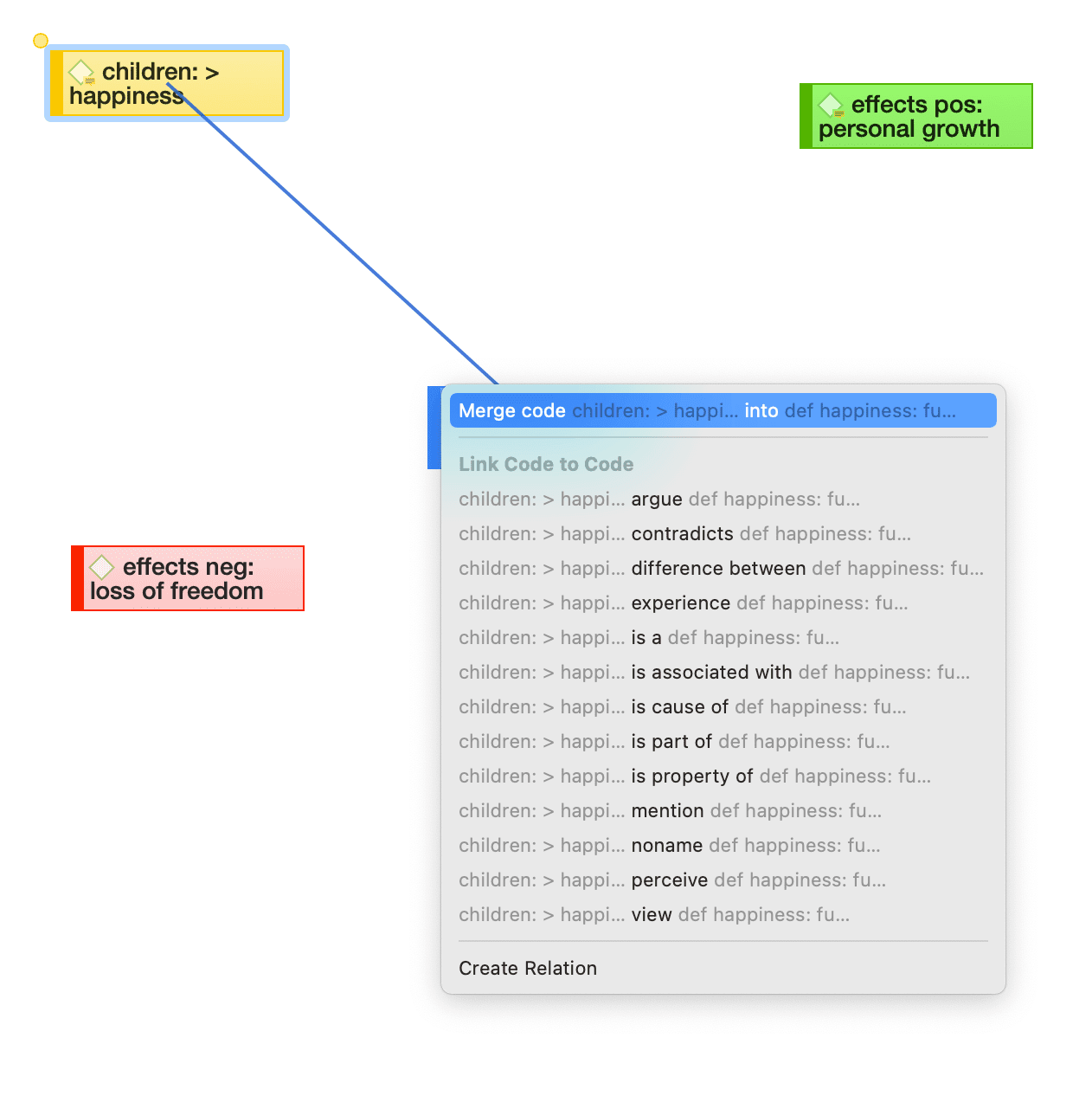
The two nodes are now linked to each other. In case you linked two codes or two quotations to each other, the relation name is displayed above the line.
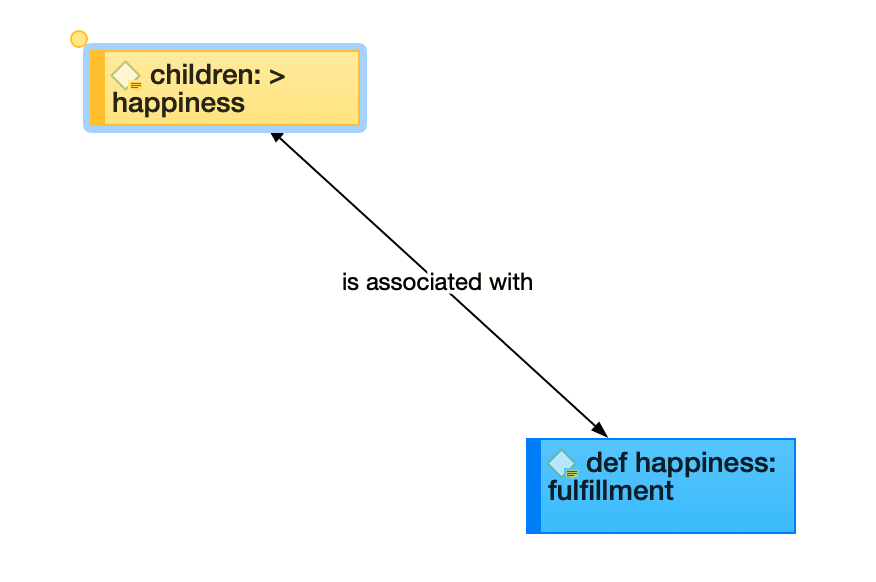
If none of the existing relations is suitable, select Create Relation and create a new relation. The new relation will immediately be applied to the link.
Editing a Link
Click on a link. If the link has a relation, click on the relation as this makes it easier to select it. A selected link is displayed in blue.
Right-click and open the secondary menu. For a named relation, you have the following options:
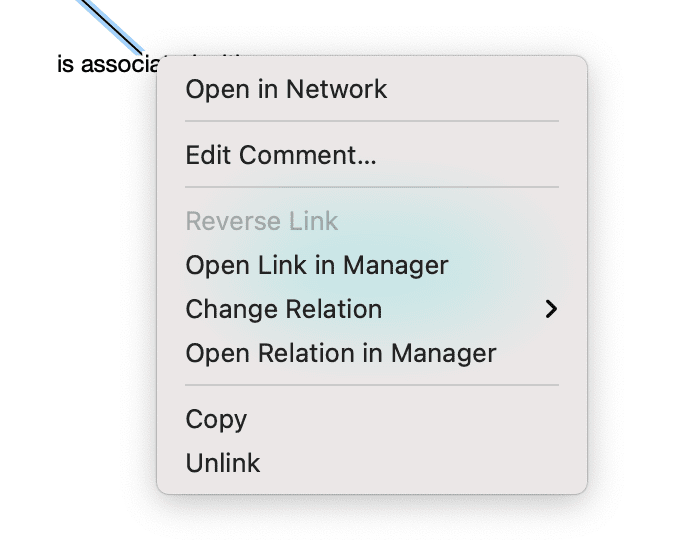
-
Edit comment: Use the comment field to explain why these two nodes are linked.
-
Reverse link: Use this option if you want to change the direction of a transitive or asymmetric link.
-
Open in Link Manager: THe Link Manager for codes lists all code-code links; the Link Manager for quotations lists all hyperlinks. In the Link Manager you can review all links, filter by relations, write comments or modify relations.
-
Change Relation: Select a different relation from the list of available relations or create a new one and apply it.
-
Open Relation in Manager: to review and modify existing relations, or to create new relations.
-
Copy: This creates a plain text description of the relation between the two entities that you paste into a comment, memo or text editor.
-
Unlink: Removes the link between the two nodes.
Linking Codes to Codes, Quotations to Quotations, Memos to Memos in Managers and Browsers
Quotations, codes and memos can also be linked to each other elsewhere, for exammple in the Manager, the Project Explorer, or the respective entity browsers.
Select one or more source items in the list pane of the Manager, in the respective sub-branches of the Project Explorer, or in the entity browsers and drag them to the target item in the same pane.
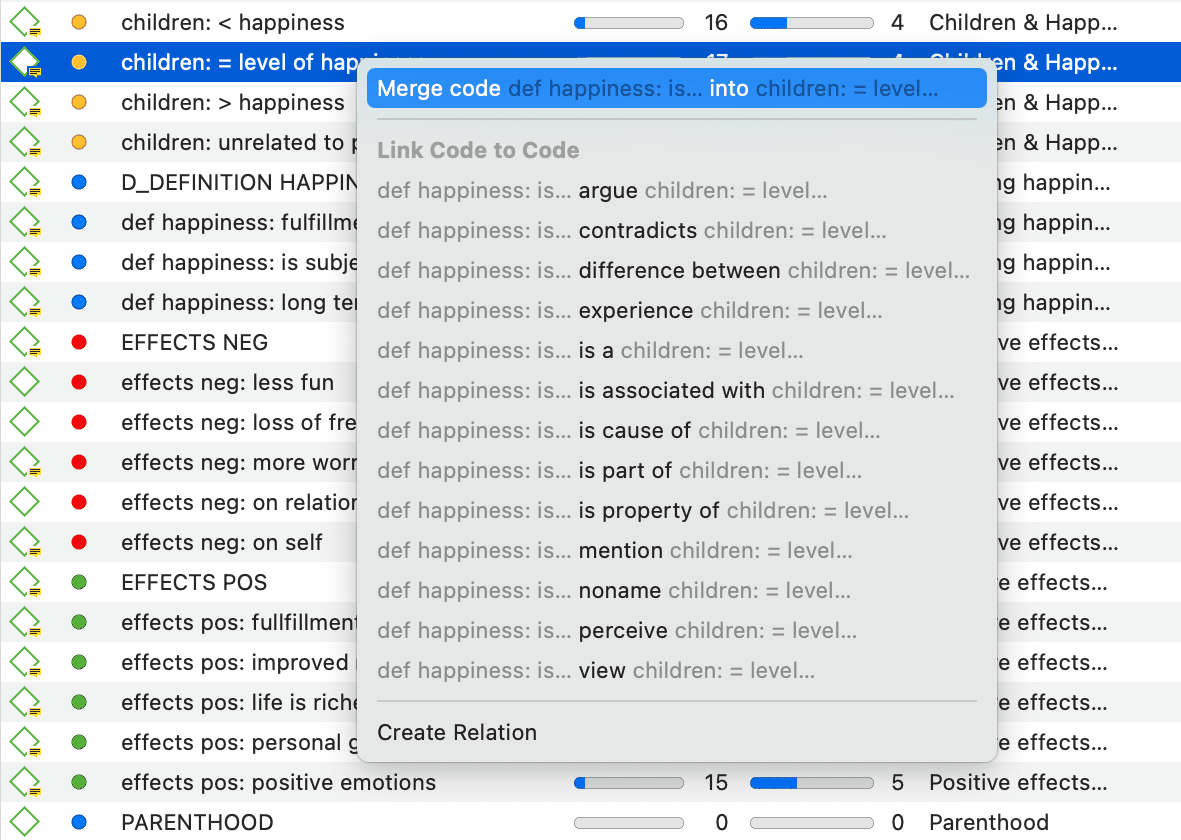
Linking two codes in the Code Manager
Select a relation from the list of relations in case you link two codes or two quotations, or select Create Relation and create a new relation.
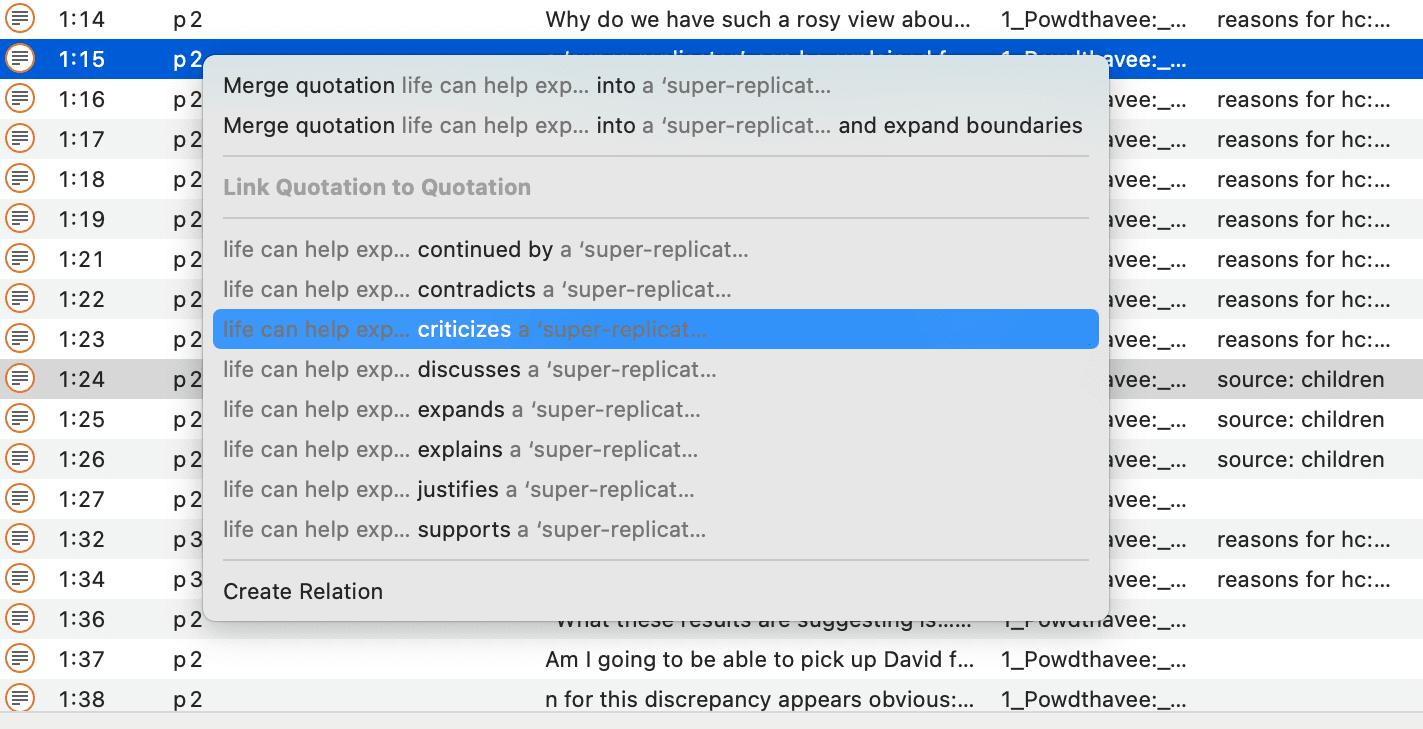
Linking two quotations in the Quotation Manager - Creating a hyperlink
Linking Entities of Different Types
When you code your data reading through a document, listening to audio data, viewing an image or video file, you are linking codes to quotations. You can also link quotations to codes in a network, but this is more exceptional rather than a regular procedure.
Linking a memo to a code in a network, or a memo to a quotation might be something you do more often. It works basically the same as linking two codes to each other. The difference is that you cannot name the link between memos and codes, or memos and quotations, or memos and memos. These are second class links as is explained in section About Nodes and Links
Note, that the following entities cannot be linked to each other:
- quotations to documents
- memos to documents (use a document comment instead)
- codes to documents (you can however view code-document connections, see View options)
- codes to code groups, document to document groups, or memos to memo groups (if you do so, the code / document / memo will become a member of the respective group)
- groups to each other (as for instance a code can be a member of multiple code groups, this would potentially create circular relations)
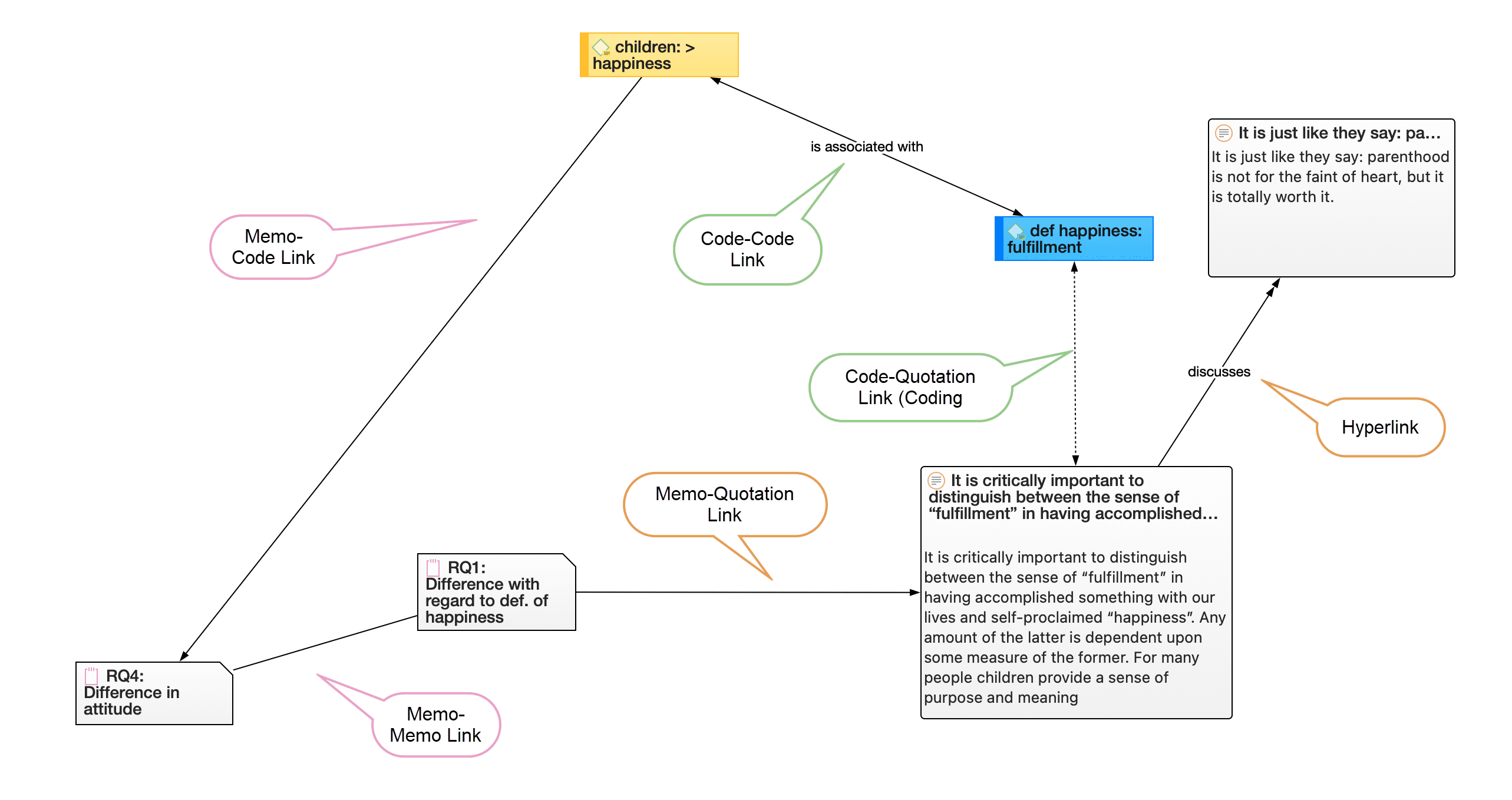
Creating Reports
You can export data in spreadsheet format or as text reports (Word or PDF format).
Export as Spreadsheet
In every manager, you find a button (the rectangular icon with an up arrow) to export the content as spreadsheet. The export is a WYSIWYG (what you see is what you get) type of report. All columns currently displayed are exported.
From Managers
To exclude a column from the report, click on the column header and deselect it.
To create a report, open the drop-down menu of the report button in the toolbar and select Export as Spreadsheet.
Use the grouping options to create different sheets for each of the selected entity, e.g. if you group a quotation report by codes, ATLAS.ti creates a separate sheet for each code and its quotation in the spreadsheet or Excel file.
From the Quotation Reader
To export the quotations listed in a Quotation Reader as spreadsheet, open the drop-down of the options button in the toolbar and select Export as Spreadsheet. The content of the report is the same as from the Quotation Manager. It contains all columns from the Quotation Manager.
From the Query Tool
To create a report, open the drop-down menu of the report button in the toolbar and select Export as Spreadsheet.
Export as Report
When using this option, you get a report in text or PDF format. It is available form all managers and the query tool. The report is configurable, this means you can select what it should contain. Before you create the report, you see a preview.
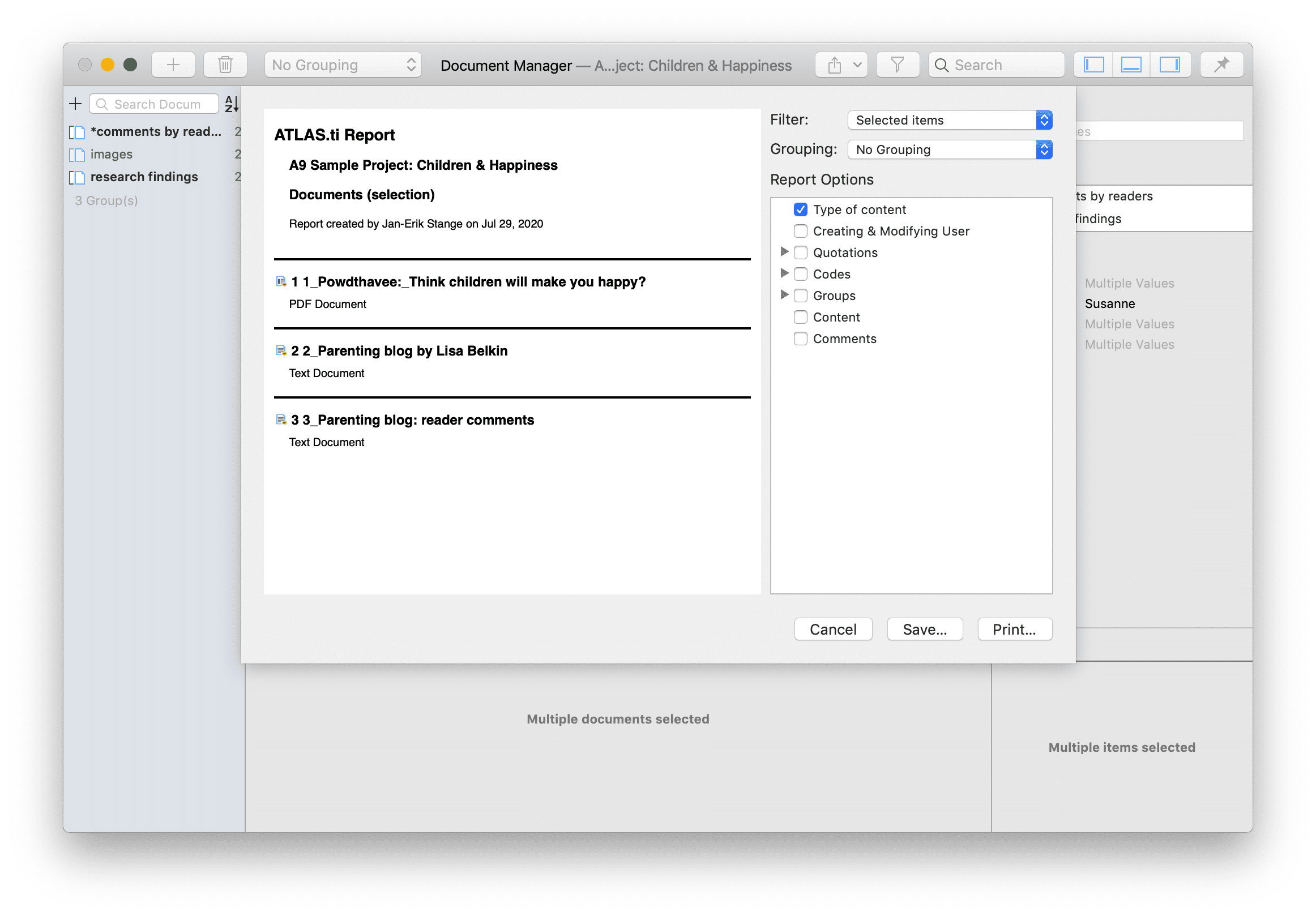
Open a Manager. Click on the drop-down menu of the report button in the toolbar and select Export as Report.
On the left-hand side you see how the report looks like given the current selections. On the right-hand side, you can select further options:
-
Filter: If you selected items before clicking on the report button, you can switch between creating a report for only the selected or all items.
-
Grouping: Depending on the entity type you have different grouping options, e.g. by code, code group or document. Select a grouping option if appropriate.
If you select to group quotations by code, and a quotation is coded by multiple codes groups, the quotations for this code will occur multiple times in the report.
If you select to group by code groups, and a code is a member of multiple code groups, the quotations for this code will occur multiple times in the report.
-
Report options: In this field, you can select which content should be displayed in the report. As soon as you select an option, you see in the preview how it will look like in the report. See below for further detail.
-
Save: This saves the report as Word document. Select a name for the report and a location.
-
Print: You can send the report directly to a printer and print it, or you can save it as PDF file. Other options are:
- Save as PostScript
- Send in Mail
- Send via Messages
- Save to iCloud Drive
- Save to Web Receipts
Appendix
The following information has been compiled for the appendix:
-
Useful Resources: Here you find links to the ATLAS.ti website, the Helpdesk, video tutorials, manuals in PDF format to download, the research blog and publications on the use of ATLAs.ti, including an article by Prof. Krippendorff about the implementation of inter-coder agreement in ATLAS.ti.
System Requirements
The system requirements are:
-
macOS 10.13 High Sierra or higher
-
min. 8 GB RAM
-
10 GB space on the hard drive
Useful Resources
The ATLAS.ti Welcome Screen contains links to manuals, sample projects and video tutorials. The News sections informs you about current developments, updates that are released, interesting papers we have come across, use cases, and our newsletter.
The ATLAS.ti Website
The ATLAS.ti website should be a regular place to visit. Here you will find important information such as video tutorials, additional documentation of various software features, workshop announcements, special service providers, and announcements of recent service packs and patches.
Getting Support
From within ATLAS.ti, select Help > Online Resources / Contact Support. Or access the Support Center directly via the above URL.
ATLAS.ti 9 - What's New
This document is intended specifically for users who already have experience using the previous version.
Video Tutorials
If you like to learn via video tutorials, we offer a range of videos covering technical as well as methodological issues.
Sample Projects
You can download a number of different sample projects from our website. Currently English and Spanish language projects are available. The projects feature different types of data sources:
- text
- image
- video
- geo data
.... and different data types:
- interview transcripts
- reports
- online data
- evaluation data
- survey
- literature review
You can use them for yourself to get to know ATLAS.ti, or you can use them for teaching purposes. If available, also the raw data are provided.
PDF Manuals
ATLAS.ti 9 Full Manual and other documentations.
Research Blog
The ATLAS.ti Research Blog plays a very important role in the development and consolidation of the international community of users. Consultants, academics, and researchers publish short and practical articles highlighting functions and procedures with the software, and recommending strategies to successfully incorporate ATLAS.ti into a qualitative data analysis process. We invite you to submit short articles explaining interesting ways of making the best use of ATLAS.ti, as well as describing how you are using it in your own research. To do so, please contact us.
Inter-coder Agreement in ATLAS.ti by Prof. Krippendorff
We have been closely working with Prof. Krippendorff on the implementation to make the original Krippendorff alpha coefficient useful for qualitative data analysis. This for instance required an extension and modification of the underlying mathematical calculation to account for multi-valued coding.. You can download an article written by Prof. Krippendorff about the implementation of the alpha family of coefficients in ATLAS.ti.
Publications
-
Friese, Susanne (2019). Qualitative Data Analysis with ATLAS.ti. London: Sage. 3. edition.
-
Friese, Susanne (2019). Grounded Theory Analysis and CAQDAS: A happy pairing or remodelling GT to QDA? In: Antony Bryant and Kathy Charmaz (Eds.). The SAGE Handbook of Current Developments in Grounded Theory, 282-313. London: Sage.
-
Friese, Susanne (2018). Computergestütztes Kodieren am Beispiel narrativer Interviews. In: Pentzold, Christian; Bischof, Andreas & Heise, Nele (Hrsg.) Praxis Grounded Theory. Theoriegenerierendes empirisches Forschen in medienbezogenen Lebenswelten. Ein Lehr- und Arbeitsbuch, S. 277-309. Wiesbaden: Springer VS.
-
Friese, Susanne, Soratto, Jacks and Denise Pires (2018). Carrying out a computer-aided thematic content analysis with ATLAS.ti. MMG Working Paper 18-0.
-
Friese, Susanne (2016). Grounded Theory computergestützt und umgesetzt mit ATLAS.ti. In Claudia Equit & Christoph Hohage (Hrsg.), Handbuch Grounded Theory – Von der Methodologie zur Forschungspraxis (S.483-507). Weinheim: Beltz Juventa.
-
Friese, Susanne (2016). Qualitative data analysis software: The state of the art. Special Issue: Qualitative Research in the Digital Humanities, Bosch, Reinoud (Ed.), KWALON, 61, 21(1), 34-45.
-
Friese, Susanne (2016). CAQDAS and Grounded Theory Analysis. Working Papers WP 16-07
-
McKether, Will L. and Friese, Susanne (2016). Qualitative Social Network Analysis with ATLAS.ti: Increasing power in a blackcommunity.
-
Friese, Susanne & Ringmayr, Thomas, Hrsg (2016). ATLAS.ti User Conference proceedings: Qualitative Data Analysis and Beyond. Universitätsverlag TU Berlin. https://depositonce.tu-berlin.de/bitstream/11303/5404/3/ATLASti_proceedings_2015.pdf
-
Paulus, Trena M. and Lester, Jessica. N. (2021). Doing Qualitative Research in a Digital World. Thousand Oaks, CA: Sage.
-
Paulus, Trena M., Lester, Jessica. N. and Dempster, Paul (2013).Digital Tools for Qualitative Research. Thousand Oaks, CA: Sage.
-
Silver, Christina and Lewins, Ann (2014). Using Software in Qualitative Research. London: Sage.
-
Konopásek, Zdenék (2007). [Making thinking visible with ATALS.ti: computer assisted qualitative analysis as textual practices 62 paragraphs. (http://nbn-resolving.de/urn:nbn:de:0114-fqs0802124)
-
Woolf,Nicholas H. and Silver, Christina (2018). Qualitative Analysis Using ATLAS.ti: The Five Level QDA Method. New York: Routledge.
Get In Touch
Social Media
You can access all social media channels from within ATLAS.ti by selecting Help > Social Media.
Stay updated with the latest news on product updates, special offers, new training materials, or interesting articles and links we find. We are also happy to hear from users via these channels. Stop by and let us know about your projects and experience with ATLAS.ti!
Stop by and let us know about your projects and experience with ATLAS.ti!
The ATLAS.ti YouTube channel offers a variety of video materials:
- Overview of the software functionality
- Recorded webinars
- Video tutorials that help you to learn the software.
Videos are available in English and Spanish.