
Named Entity Recognition (NER)
In natural language processing, Named Entity Recognition (NER) is a process where a sentence, or a chunk of text is parsed through to find entities that can be put under categories like person, organization, location, or miscellaneous like work of arts, languages, political parties, events, title of books, etc.
Currently supported languages are: English, German, Spanish and Portuguese
You can think of it like a special auto coding procedure, where you as the user do not enter a search term. Instead, ATLAS.ti goes through your data and finds entities for you.
You can select which entities you want to search for:
- person
- organization
- location
- miscellaneous (work of arts, languages, political parties, events, title of books, etc.)
After the search is completed, ATLAS.ti shows you what it found, and you can make corrections. In the next step you can review the results in context and code all results with the suggested codes, or decide for each hit whether to code it or not.
To open the tool:
Select the Search & Code tab and from there Named Entity Recognition.
inst
Select documents or document groups that you want to search and click Continue.
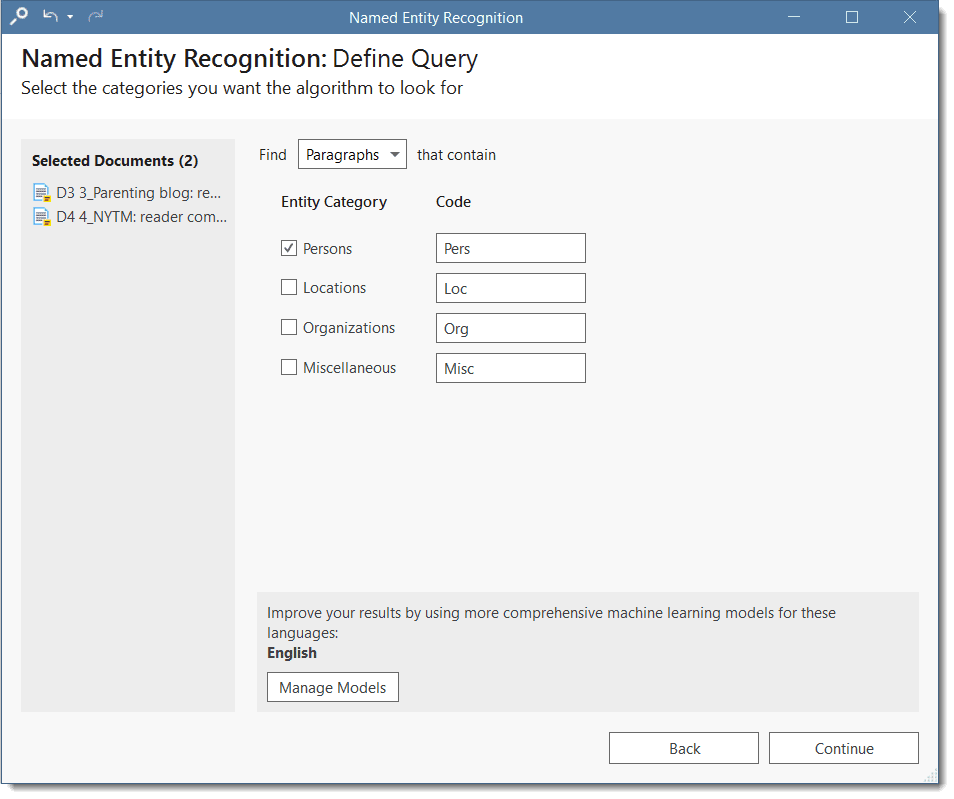
Select whether the base unit for the search and the later coding should be paragraphs or sentences, and which entity category you want to search for.
inst
ATLAS.ti proposes prefixes for the code label for each category. If you want different ones, you can change them here.
Manage Models: If you want to improve your results, you can download and install a more comprehensive model. Currently, it is available for German and English language texts. More languages will be added in the future. The size of the German model is ~ 230 MB and for the English model ~ 110 MB.
Click on Manage Models if you want to install or uninstall an extended model.
Click Continue to begin searching the selected documents. On the next screen, the search results are presented, and you can review them.
Reviewing Search Results
If you selected to search for all entity types (persons, location, organization and miscellaneous), you can review them all together, or just focus on one entity at a time. To do so, deactivate all other entity types.
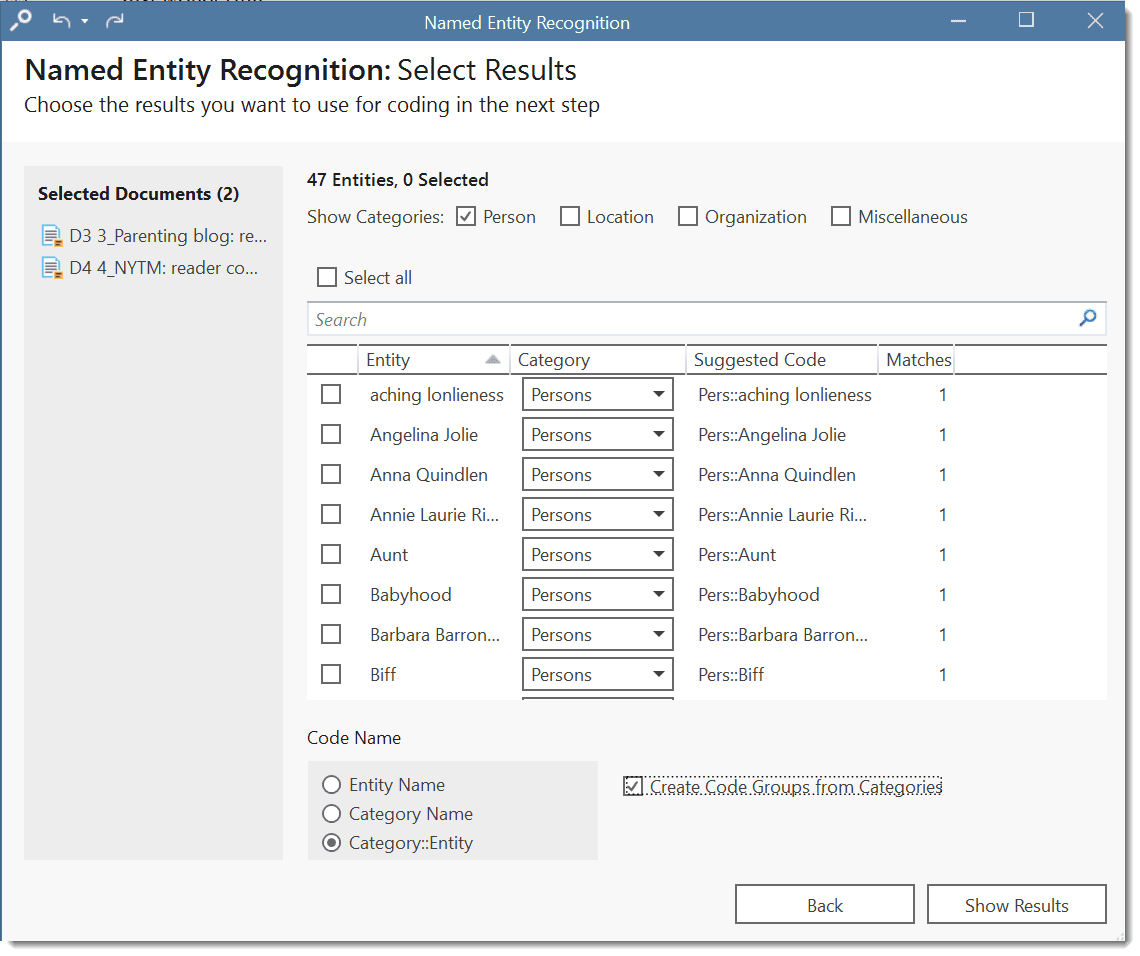
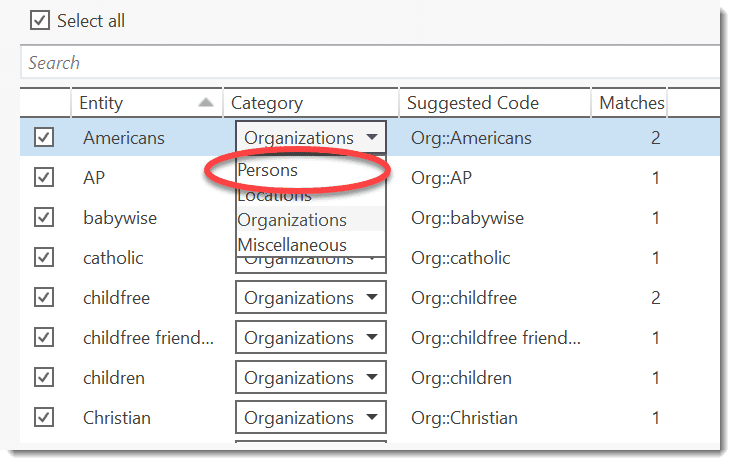
Select all results that you want to code. If a result is interesting but comes up in the wrong category, you can change the category in the second column of the result list. In the third column, the suggested code name is listed.
Code Name
You have three options for the code name:
-
Entity Name: The search hit is used as name without pre-fix. If you select this option, the resulting codes are listed in alphabetic order in the Code Manager. It is recommended to use this option in combination with creating code groups for each category.
-
Category Name: If you use this option, all search hits will be combined under one code using the category label as name.
-
Category::Entity: The category name, and the search hit is used as code name (recommended option).
You also have the option to group all codes of a category into a code group. This option is useful if you selected entity names only, or category plus entity as code name.
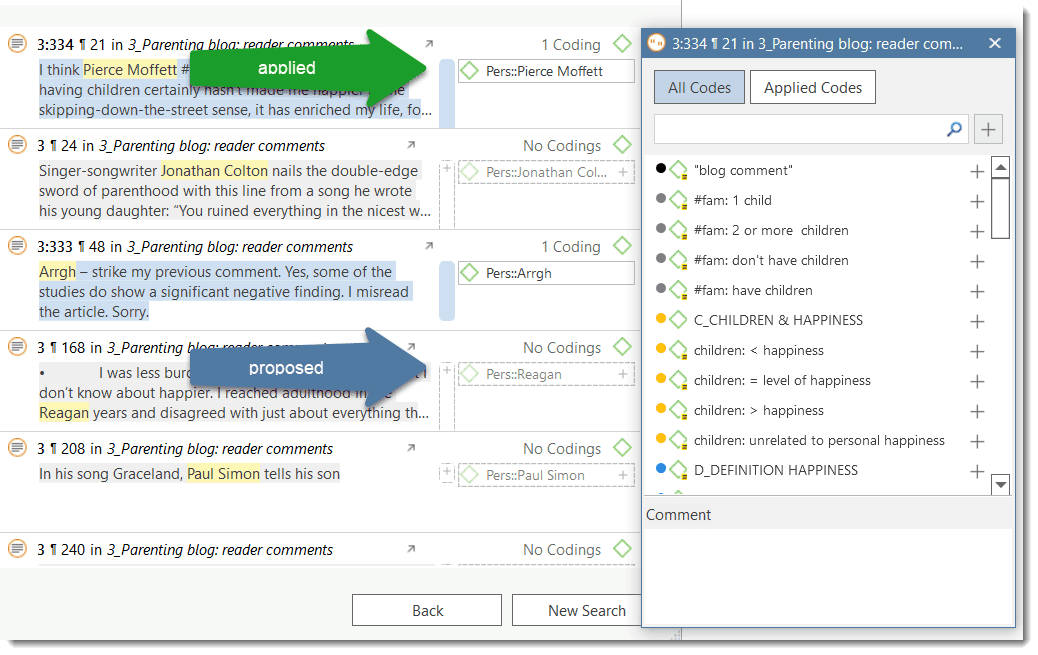
Click Show Results to inspect the results in context.
The result page shows you a Quotation Reader indicating where the quotations are when coding the data with the proposed code. If coding already exist at the quotation, it will also be shown.
By clicking on the eye, you can change between small and large previews.
You can code all results with one of the proposed codes, or with all proposed codes at once.Alternatively, you can go through, review each data segment and then code it by clicking on the plus next to the code name.
You can code all results at once by clicking on Apply Proposed Codes, and from there you either select Apply All Codes, or you select one of the codes from the list.
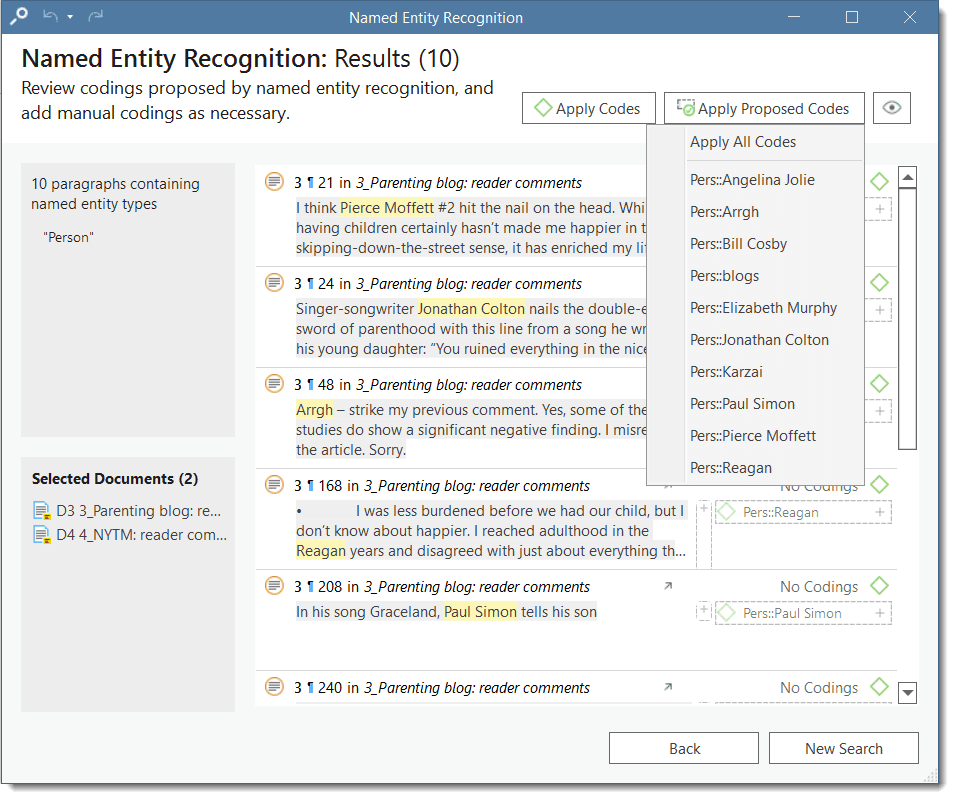 Depending on the area you have selected at the beginning, either the sentence or the paragraph is coded.
Depending on the area you have selected at the beginning, either the sentence or the paragraph is coded.
The regular Coding Dialogue is also available to add or remove codes.
The Search Engine Behind NER
ATLAS.ti uses spaCy as its natural language processing engine. More detailed information can be found here.
Input data gets processed in a pipeline - one step after the other as to improve upon the derived knowledge of the prior step. Click here for further details.
The first step is a tokenizer to chunk a given text into meaningful parts and replace ellipses etc. For example, the sentence:
“I should’ve known(didn’t back then).” will get tokenized to: “I should have known ( did not back then ).“
The tokenizer uses a vocabulary for each language to assign a vector to a word. This vector was pre-learned by using a corpus and represents a kind of similarity in usage in the used corpus. Click here more information.
The next component is a tagger that assigns part-of-speech tags to every token and lexemes if the token is a word. The character sequence “mine”, for instance, has quite different meanings depending on whether it is a noun of a pronoun.
Thus, it is not just a list of words that is used as benchmark. Therefore, there is also no option to add your own words to a list or to see the list of words that is used.
The entity recognizer is trained on wikipedia-like text and works best in grammatically correct, encyclopedia-like text. We are using modified pre-trained/built-from-the-ground-up models - depending on the language.