
Code-Document Table: Relative Frequencies
Relative frequencies are useful for comparing code distributions across or within documents or document groups, as percentages are easier to comprehend.
If documents are of unequal length, or if document groups have an unequal number of members, it is recommended to normalize the counts as absolute counts may distort the results. See Data Normalization.
Within Group Comparison: Column Relative Frequencies
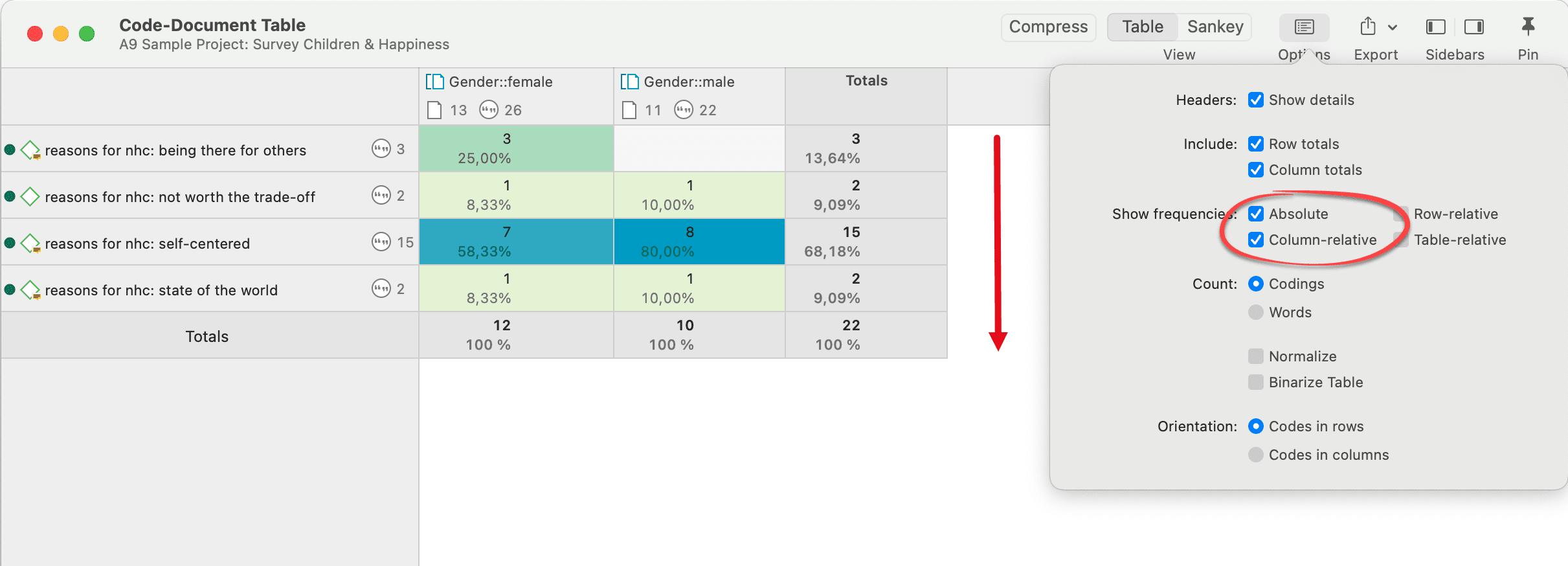 Code-Document Table showing an example for within group comparison
You must read this table from top to bottom along the columns. It shows the distribution of the selected codes within two document groups.
The results of the table could be summarized as follows: As reasons for not having children, women have mostly mentioned "self-centered" (58%) and "being there for others" (25%). For men, "self-centered" was also the main reason (80%), followed by "not worth the trade-off" and "state of the world" (both 10%).
Apart from the fact that these data are completely fictitious, this summary shows that percentages can inflate the results quite a bit. There is only one quote for "not worth the trade-off" and "state of the world". In terms of percentage, it looks like a lot more. Use this option with care. It is very useful for larger data sets and if you have a higher number of quotations.
Code-Document Table showing an example for within group comparison
You must read this table from top to bottom along the columns. It shows the distribution of the selected codes within two document groups.
The results of the table could be summarized as follows: As reasons for not having children, women have mostly mentioned "self-centered" (58%) and "being there for others" (25%). For men, "self-centered" was also the main reason (80%), followed by "not worth the trade-off" and "state of the world" (both 10%).
Apart from the fact that these data are completely fictitious, this summary shows that percentages can inflate the results quite a bit. There is only one quote for "not worth the trade-off" and "state of the world". In terms of percentage, it looks like a lot more. Use this option with care. It is very useful for larger data sets and if you have a higher number of quotations.
Whether you need to select row or column relative frequencies depends on which way around the table is displayed. If documents/document groups are listed as rows and the codes as columns, you use row relative frequencies for a within group comparison.
Across Group Comparisons: Row Relative Frequencies
EXAMPLE WITH NORMALIZATION
Document 3 is about twice as long as document 4 in the Children & Happiness sample project. Thus, the number of codings regarding a specific topic can be expected to be higher as well in document 3. If we compare how often positive and negative effects of parenting were mentioned in both documents, normalizing the data will give a more accurate picture.
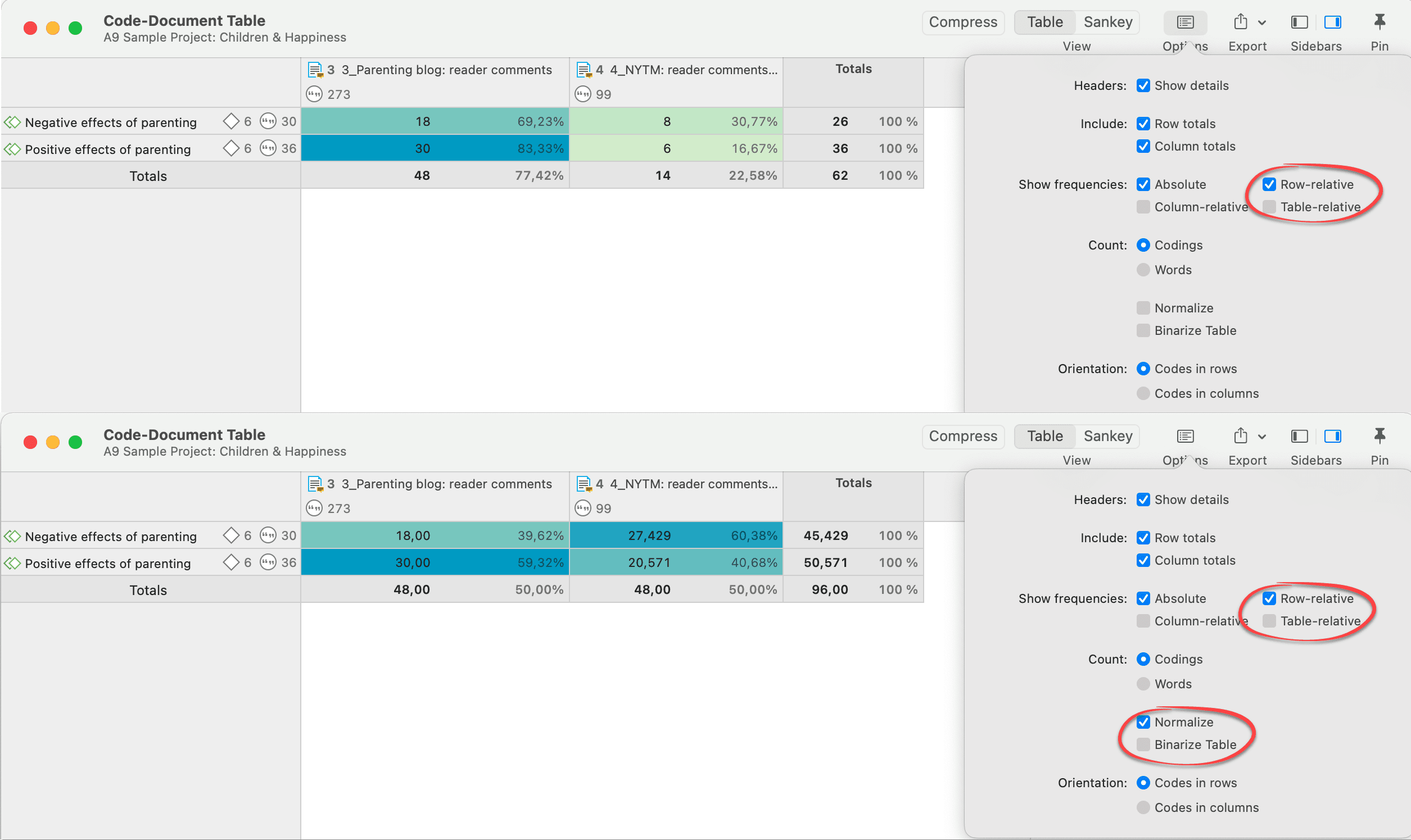
Relative frequencies in combination with normalized data (Across group comparison)
Looking at the data without normalization it looks like that the readers of the NYTM article mention much fewer positive and negative effects of parenting. After normalization, this interpretation needs to be adjusted. The reader of the NYTM article mentioned more negative effects of parenting as compared to the readers of parenting blog: 60,36% as compared to 39.62%; and fewer positive effects (40,68% as compared to 59,32%).
Total Relative Frequencies
If you select total relative frequencies, the calculation is based on the total number of codings of all selected codes in the table.
In the example below, these are 94. When comparing how much readers of the parenting blog and the NYTM article have written about reason for having and not having children, then the distribution is as follows:
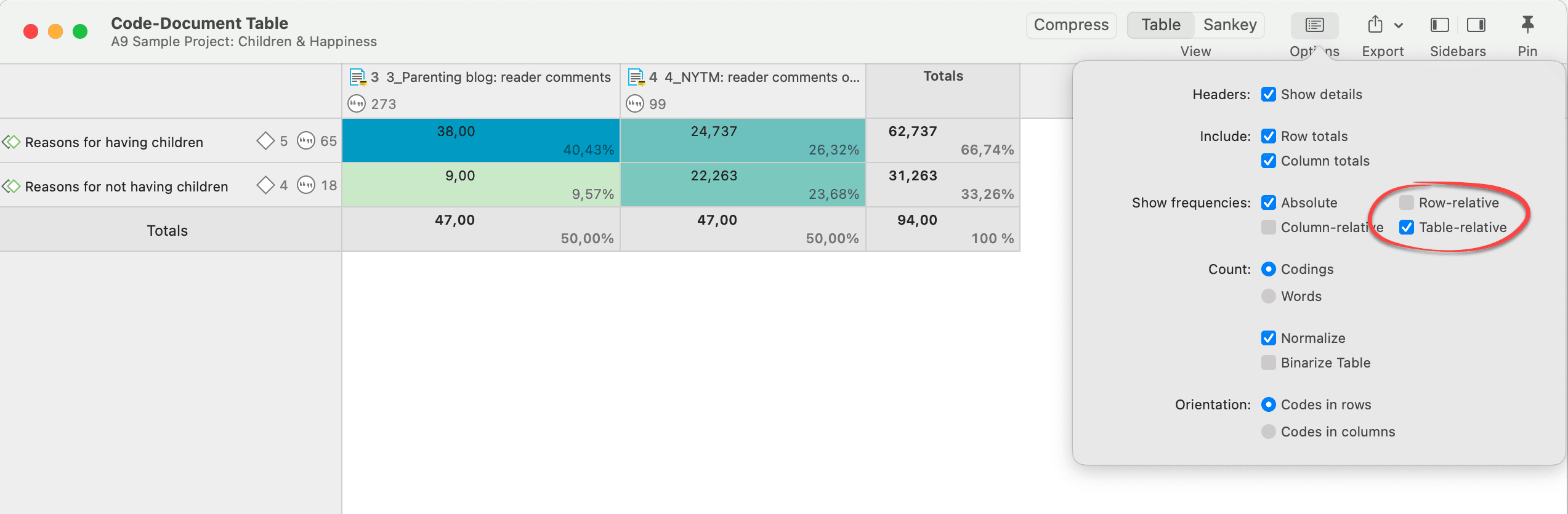
Example application of total relative frequencies
-
readers of the parenting blog have given 38/94 = 40,43% of the reasons for having children and 9/94=9,57% of the reasons for not having children
-
readers of the NYTM article have contributed 24,7/94=26,32% of the reasons for having children and 22,26/94=23,68% of the reasons for not having children (the data have been normalized). Thus, comparatively, the readers of the NYTM articles have given quite a bit more reasons for not having children, which fits the results reported above that they also wrote more about negative effects of parenting.
You can display all values: absolute frequencies and all relative frequencies in one table by selecting all options. It depends on the purpose for which you want to use the table. For interpreting the data, it is probably easier if you look at each of the relative frequency counts separately. For a comprehensive report for an appendix, you may want to export the table with all options included.